







こんにちは、ナナです。
「オーバーロード」とは多重定義のことであり、「関数のオーバーロード」とは同一の関数名を複数定義できることを示します。
C言語ではできなかったこの仕組みを、C++ではどのように実現しているのかも含めて解説しましょう。
オーバーロードで同一名の関数を複数定義してみよう
同じ関数を複数定義できるって不思議ですね。C++ではそんなことができるんですか。
実際に使い方を見せてほしいです。
実はすでに皆さんは「オーバーロード」を使っているんですよ。その例を踏まえて「オーバーロード」の使い方を覚えましょう。
オーバーロードの代表「コンストラクタ」
実はここまでのカリキュラムで、すでにオーバーロードは活躍しています。それが「コンストラクタ」です。
#include <stdio.h>
class POS
{
public:
int x;
int y;
POS(void); // 引数なしコンストラクタ
POS(int tmpx, int tmpy); // 引数ありコンストラクタ
};
// 引数なしのコンストラクタ定義①
POS::POS(void)
{
x = 0;
y = 0;
}
// 引数ありのコンストラクタ定義②
POS::POS(int tmpx, int tmpy)
{
x = tmpx;
y = tmpy;
}「コンストラクタ」はクラス名を持つメンバ関数ですが、よくよく見てみると関数名「POS」が2つ定義されていますよね。
これこそが「関数のオーバーロード」です。
「関数のオーバーロード」を定義できる条件
関数のオーバーロードを定義するには、とある条件があります。
その条件とは、
引数の構成(個数やデータ型)が異なる場合に限り、同一関数名を定義できる
ということです。
戻り値のデータ型は、この条件に含まれないことに注意しましょう。
普通の関数でも、クラスに属するメンバ関数でもオーバーロードすることができます。
関数名は一緒ですが、引数の構成が異なることにより別の関数と認識できるのです。
関数のオーバーロード定義例
それでは「printNum」関数を3つ定義してみます。引数の違いに着目してください。
#include <stdio.h>
// 関数①
void printNum(int num)
{
printf("関数① int:%d\n", num);
}
// 関数②
void printNum(double num)
{
printf("関数② double:%lf\n", num);
}
// 関数③
void printNum(int num1, double num2)
{
printf("関数③ int:%d double:%lf\n", num1, num2);
}
int main()
{
printNum(10); // 関数①の呼び出し
printNum(3.14); // 関数②の呼び出し
printNum(50, 1.23); // 関数③の呼び出し
return 0;
}関数① int:10
関数② double:3.140000
関数③ int:50 double:1.230000このように呼び出す側の引数の与え方によって、呼び出される関数が変化します。これが関数のオーバーロードの動きです。
関数のオーバーロードの便利さとは?
同じ関数名の関数を定義したい時って、そもそもどんな時なんですか?
プログラミングをしてても、あまりこれまで意識したことがなかったんですが、便利なんですか?
関数名には、その関数の処理概要をタイトルとして付けますよね。
つまり、「関数のオーバーロード」は概要は一緒だけど、引数によって動きを少し変えたいといったときに便利ですね。
それでは、オーバーロードの実例をプログラムで示しましょう。
座標を管理する「POS」クラスに対して「座標を設定する」という概要のメンバ関数を複数用意してみます。
関数オーバーロードで「座標の設定」を定義
「座標を設定」という処理概要は「X座標とY座標を設定する」ということです。しかし、X・Y座標を設定する方法はいくつかの種類があってもおかしくありません。
このように、「座標を設定したい」という概要に対して、様々な方法が考えられるのです。
それでは、実際のプログラムでこれらの方法をメンバ関数として定義してみましょう。
#ifndef POS_H
#define POS_H
// 3D座標管理構造体
typedef struct
{
int x;
int y;
int z;
} S_Pos3D;
class POS
{
private:
int x;
int y;
public:
POS();
void setPos();
void setPos(int x, int y);
void setPos(S_Pos3D pos3d);
};
#endif // POS_Hヘッダファイルには「POS」クラスと3D座標を管理する「S_Pos3D」構造体を定義します。メンバ関数として、3種類の「setPos」関数を用意します。
#include "POS.h"
POS::POS()
{
this->x = 0;
this->y = 0;
}
// 座標クリア
void POS::setPos()
{
this->x = 0;
this->y = 0;
}
// 任意座標の設定
void POS::setPos(int x, int y)
{
this->x = x;
this->y = y;
}
// 3D座標からの座標設定
void POS::setPos(S_Pos3D pos3d)
{
this->x = pos3d.x;
this->y = pos3d.y;
}このように「setPos」という座標設定としてのメンバ関数名は同じですが、引数によって様々なバリエーションを用意することができます。
クラスを使う側からすると、「setPos」というメンバ関数を探せば座標設定に関するバリエーションを把握することができるようになります。
もしも、オーバーロードができなかったとしたら「clearPos」「setPos」「setPosFrom3D」といったバラバラの関数名を定義することになり、座標設定のバリエーションを把握するのも大変になります。
一例でしかありませんが、クラスのメンバ関数はクラスを使う側のユーザーに対して、より自然な形でサービスを提供するにはどうしたらよいか?を考えることです。
オーバーロードでそれが実現できるのであれば、活用すればよいのです。
関数のオーバーロードを定義するときの注意点
「関数のオーバーロード」を使えば、同じ名前の関数でも何個も作れるんですねー。作りまくりですよ~。
作るのは自由だけどね、場合によって注意してほしいケースもあるから気を付けてね。
概要が同じものをオーバーロードで定義すること
関数名が同じということは、使う側からすると引数は異なるが実施してくれるサービス内容は同じものを期待しているということです。
先ほどの座標設定を例にすると、setPos関数の中の1つが座標設定以外の仕事をしてしまったとなれば、他のsetPos関数とサービス内容が異なるということが起きます。
それは関数を使う側を混乱させてしまう状況になるのです。
同系統のデータ型のみが異なるオーバーロードは危険
例えば整数型にはchar型・short型・int型・long型などいくつかの種類があります。このような同一系統のデータ型の違いしかないオーバーロードは扱いに気を付ける必要があります。
#include <stdio.h>
void printNum(int num) // 整数型系統
{
printf("int:%d\n", num);
}
void printNum(long num) // 整数型系統
{
printf("long:%d\n", num);
}
void printNum(float num) // 浮動小数点型系統
{
printf("float:%f\n", num);
}
void printNum(double num) // 浮動小数点型系統
{
printf("double:%lf\n", num);
}
int main()
{
printNum(100);
printNum(3.14);
return 0;
}int:100
double:3.140000結果としては「int型」「double型」の関数が呼び出されています。
このように同系統のデータ型のみ異なるオーバーロードは人の目には一見どれが呼び出されるか判断が付きづらくなります。
その関数が本当に必要なのか?曖昧な指定とならないか?といった視点で関数は定義しましょう!
同一の関数名を定義できる仕組み:名前修飾(name mangling)
C言語では同一の関数名は使えませんよね?どうして、C++では同一の関数名が使えるんですか?
C++では、名前修飾(ネームマングリング)と呼ばれる仕組みを利用して実現しているんですよ。
その仕組みを解説しましょう!
どうしてC言語では同じ名前の関数が定義できないのか?
皆さん、そもそもなぜ同じ名前の関数は定義できないのでしょう?
それは、関数の定義側と呼び出し側が「関数名」によって紐づいているからです。
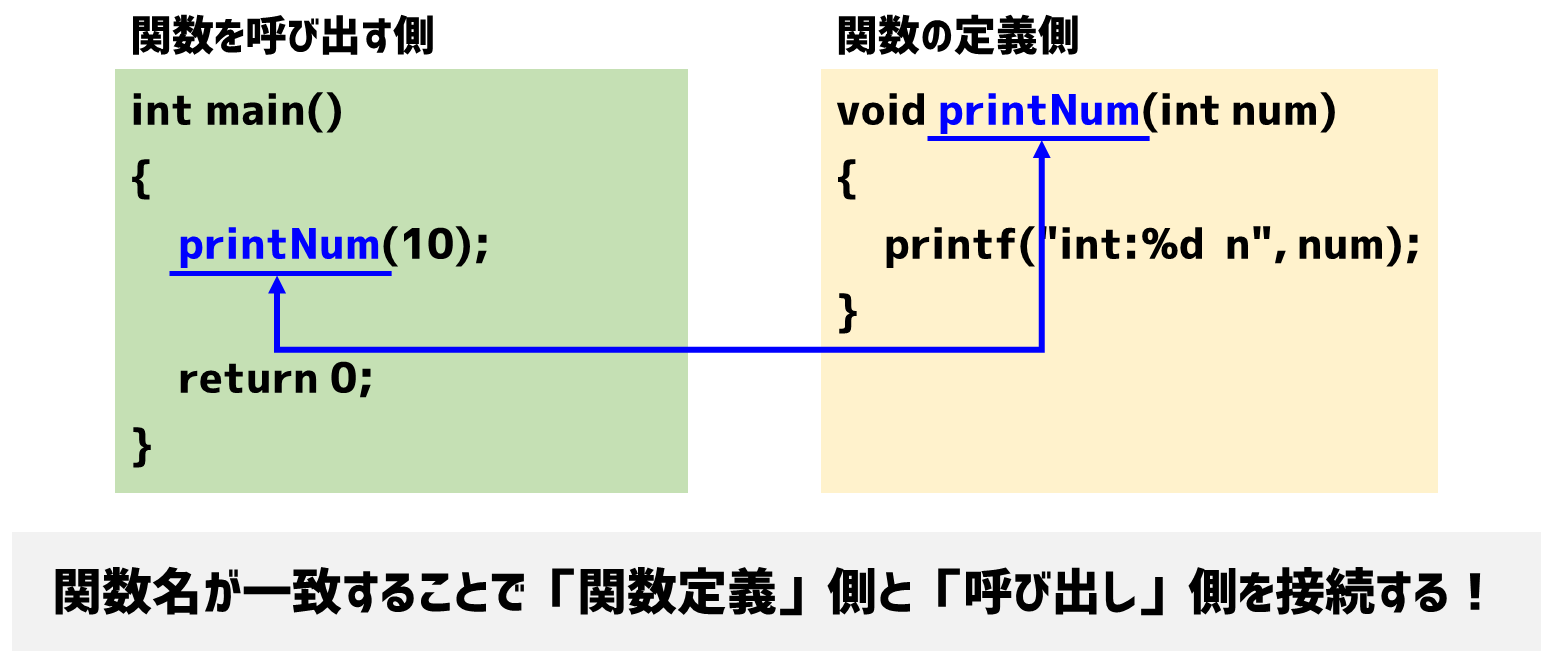
この接続は「リンカ」によって行われます。リンカの詳細は『C言語 リンカの役割【リンクエラーが起きた時の対処方法】』を読んでおくとよいでしょう。
それでは同じ名前の関数が2つあった場合どうなるかというと、この「リンカ」がどっちの関数と接続したらいいのかわからなくなるわけです。
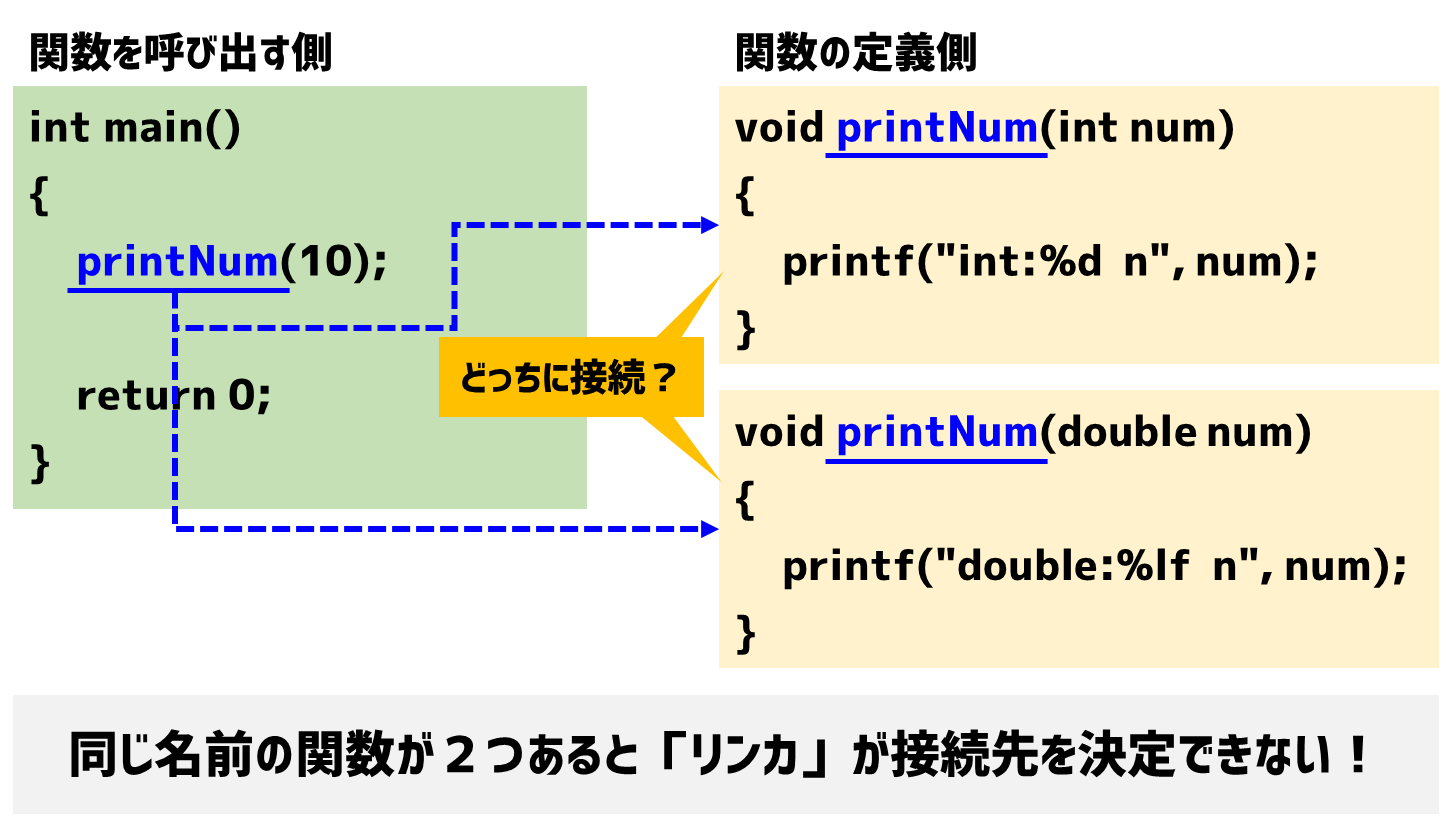
そのため、C言語においては同名の関数を定義できないのです。
C言語の仕組みを理解した上で、C++で「オーバーロード」をどのように実現しているかの謎を紐解いていきましょう!
C++のオーバーロードの仕組み
C++においても「リンカ」が行う仕事は関数名を接続することです。それでは、C言語と一体何が変わったのでしょう?
それは、コンパイラによる名前修飾(ネームマングリング)です。C++コンパイラは、皆さんが決めた関数名を加工してリンカに渡すのです。
それではどのような名前になっているかを、先ほどのプログラムで実際に確認してみましょう。Visual Stuidoのメニューバーにある[プロジェクト]-[(プロジェクト名)のプロパティ]を開きます。
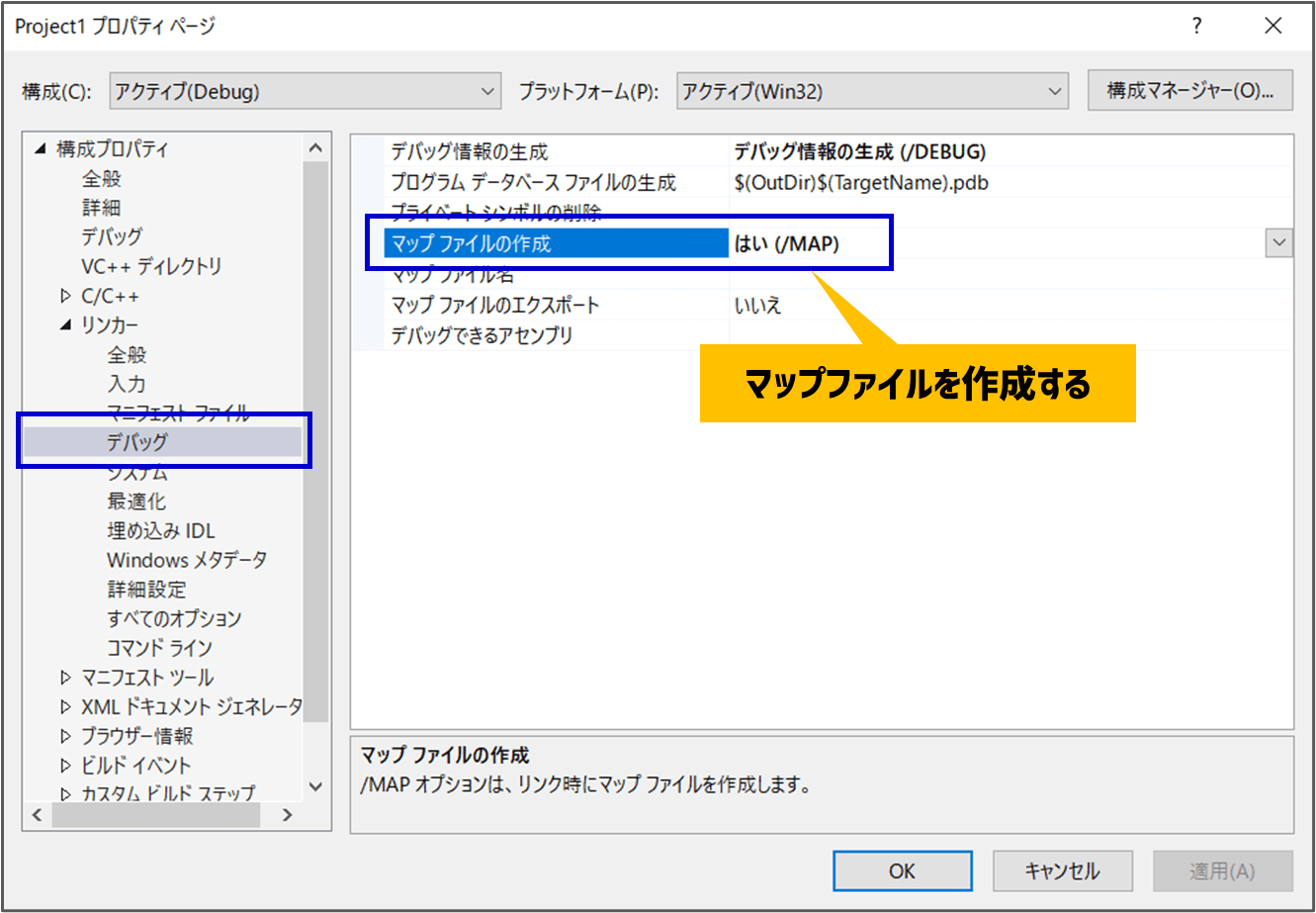
[リンカ]-[デバッグ]の中にある「マップファイルを作成する」を「はい」の設定に変更します。これによってリンカが、マップファイルにシンボル情報を出力してくれます。
マップファイルは、「ビルド」をすることで自動で生成されます。プロジェクトフォルダにあるdebugフォルダの中に「(プロジェクト名).map」の形式でファイルが作られます。
0001:00010000 __enc$textbss$end 00411000 <linker-defined>
0002:00000730 ?printNum@@YAXH@Z 00411730 f main.obj
0002:00000790 ?printNum@@YAXHN@Z 00411790 f main.obj
0002:00000800 ?printNum@@YAXN@Z 00411800 f main.obj
0002:00000870 __JustMyCode_Default 00411870 f i main.objこのように、先ほど定義した「printNum」関数は全て別名の名前で定義し直されているのです。
皆さんが作ったソースファイル上では同じ関数名ですが、コンパイラによって全て別の名前の関数に置き換えられているのです。
これによって「リンカ」は呼び出し元と関数定義を紐づけることができるようになるのです。
名前修飾(ネームマングリング)の規則性
名前修飾のルールはコンパイラが決めることなので、コンパイラによって名前の付け方は変化します。今回はVisual Studioのコンパイラの結果を見てみましょう。
| 名前修飾結果 | 関数プロトタイプ |
|---|---|
| ?printNum@@YAXXZ | void printNum(); |
| ?printNum@@YAHXZ | int printNum(); |
| ?printNum@@YAXH@Z | void printNum(int); |
| ?printNum@@YAXHN@Z | void printNum(int, double); |
| ?printNum@@YAXDFHJ@Z | void printNum(char, short, int, long); |
| ?printNum@@YAXEGIK@Z | void printNum(unsigned char, unsigned short, unsigned int, unsigned long); |
| ?printNum@@YAXMN@Z | void printNum(float, double); |
| ?printNum@@YAX_J_K@Z | void printNum(long long, unsigned long long); |
@マークで囲まれた一部の英字が、戻り値と引数のデータ型と順番を表しています。
| 英字 | データ型 |
|---|---|
| D | char |
| E | unsigned char |
| F | short |
| G | unsigned short |
| H | int |
| I | unsigned int |
| J | long |
| _J | long long |
| K | unsigned long |
| _K | unsigned long long |
| M | float |
| N | double |
| X | void |
並べてみると、アルファベット順にデータ型を当てはめているのがわかりますね。
このように「名前修飾」とは、関数の戻り値と引数情報を元にシステムで一意となる関数名を作り出すことなのです。
どのコンパイラでもそれぞれのルールに従って、引数・戻り値に関する情報を関数名に付与して独自の名前を作り出すのです。
Q&A:名前空間に関するよくある質問
Q:どうして戻り値のデータ型はオーバーロードの条件に含まれないの?
そもそも「関数の型」って、引数の構成と戻り値のデータ型で決まるんですよね。
戻り値のデータ型が違ってればオーバーロードできてもよさそうじゃないですか?どうしてできないんですか?
オーバーロードとは関数を呼び出す側において、呼び出し先の関数を特定できるのかがポイントなんです。
戻り値のデータ型が違うだけでは、区別がつかないからなんですよ。
例えば次のような戻り値のデータ型のみが異なる関数があったとします。
int testFunc()
{
return 100;
}
float testFunc()
{
return 3.13;
}関数を呼び出す側において、戻り値を受け取るのか捨てるのかは呼び出し側に権利があります。次のように、戻り値を受け取らなかったとしましょう。
int main()
{
// 戻り値を受け取らない関数呼び出し
testFunc();
return 0;
}この場合、どちらの関数を接続すべきなのか判断できる材料がないのです。
つまり「オーバーロード」では、絶対に指定が必要な「引数」は判断材料として利用できるが、受け取らない可能性がある「戻り値」は判断材料として使えないということなのです。
クラスに対する演算子を関数化する「演算子のオーバーロード」を学びましょう。


C++のカリキュラムを順に学びたい方はこちらからどうぞ~