







こんにちは、ナナです。
C言語のプログラムは「ソースファイル」と「ヘッダファイル」の2種類で構成されます。
それぞれのファイルには「どこに何を書くべきか?」というのが暗黙的に決まっており、このルールを知らないと予期せぬビルドエラーに悩まされることになります。
本記事ではヘッダファイルには、いったい何を書くべきかに焦点を当てて解説します。
ファイルの構成について知りたい方は『C言語 ファイル分割の考え方【何を基準に分けるのかを解説】』のまとめ記事を読むとよいでしょう。
本記事では次の疑問点を解消する内容となっています。
では、ヘッダファイルの書き方を学んでいきましょう。
「ヘッダファイル」の存在理由と利用目的
師匠!「ヘッダファイル」って何のためにあるんですか?
「ソースファイル」と「ヘッダファイル」の役割の違いがよくわかりません。
「ヘッダファイル」とは、ファイルの拡張子が「.h」となっているファイルのことだね。
ここまでプログラムを作ってきて、この「.h」が登場したシーンって覚えてるかな?
皆さんは、ここまででたくさん「ヘッダファイル」のお世話になっていますが、どこで登場したのかを覚えていますか?
「ヘッダファイル」はC言語のプログラムにおいて、いったいどのような役割があるのでしょう。
「ヘッダファイル」はインクルードされるためのファイル
皆さんはここまでプログラムを書く際に、「stdio.h」と呼ばれるヘッダファイルを毎回インクルードしてきましたね。
#include <stdio.h>
int main(void)
{
printf("Hello");
return 0;
}このように「ヘッダファイル」とは、
インクルードされるために用意されたファイル
のことなんです。
インクルードとはプリプロセッサの機能の1つでしたね。
忘れてしまった人は『C言語 include【インクルードで起こる変化の正体を解説】』の記事をもう一度見直しましょう!
ヘッダファイルをインクルードする理由
それではなぜ、「ヘッダファイル」というものをインクルードするのでしょうか?
それは、ソースファイルにおいて「とある機能を利用する際に必要な情報を取り込むため」に行っているのです。
#include <stdio.h>
int main(void)
{
printf("Hello");
return 0;
}このプログラムには、printf関数という機能を利用してディスプレイに「Hello」の文字列を表示しています。
main.cというソースファイルから、「printf関数」という機能を利用するためには「stdio.h」という情報を取り込む必要があるのです。
使いたい機能に応じて、必要なヘッダファイルをインクルードすることで利用できるようになります。
つまり、皆さんが「とある機能を他の人に利用してもらいたい」と思ったときは、独自のヘッダファイルを作る必要があるということになります。
ヘッダファイルには、「とある機能を使うために必要な情報」が書かれているということですね。さぁそれはいったいどのような情報なのでしょうか?
順番に解説していきましょう!
ヘッダファイルに書くべき情報とは
師匠!ヘッダファイルは「とある機能を使うための情報を書く」といっても、いったい何を書いたらいいのかが全然わかりません。
私はいったい、何をどこに書けばいいのですかっ!適当に書いちゃえばいいのですか?
適当に書くのはよくないね。C言語で必要な部品たちは、書くべき場所が決まってるんだよ。
だから、そのルールを知ることだね。それがわかればルール通りに書けばいいだけだよ。
「変数定義」「構造体定義」「プロトタイプ宣言」など、ここまで様々なC言語の部品が登場しました。
ヘッダファイルには、いったい何をどこに書くべきなのかを示しましょう。
ヘッダファイルの構成部品
ヘッダファイルは、次の構成部品で定義します。
つまり、これらの情報こそがソースファイルからインクルードされることによって、とある機能を利用できるようにするための情報なのです。
部品を配置してよいかの判断リスト
次のリストは、C言語における主な部品一覧です。ヘッダファイルに書くものは『〇』のものです。
| 部品 | 配置可否 | 役割 |
|---|---|---|
| 多重インクルード防止 | 〇 | ヘッダファイルを多重にインクルードされるのを防止 |
| ヘッダファイルインクルード | 〇 | #includeによる外部ファイルのインクルード |
| マクロ定義 | 〇 | #defineによる定数定義 |
| 型定義 | 〇 | 構造体、列挙型、共用体のデータ型定義 |
| プロトタイプ宣言 | 〇 | 関数のプロトタイプ宣言 |
| グローバル変数外部参照宣言 | 〇 | 外部ファイルへ公開するグローバル変数の参照宣言 |
| グローバル変数定義 | × | グローバル変数の実体定義 |
| 関数定義 | × | 関数の実体定義 |
ヘッダファイルで注意したいのが、
「グローバル変数の定義」と「関数定義」を含めてはいけない
ことです。
「変数定義」と「関数定義」は絶対ヘッダファイルには含めてはなりません。これはやってしまいがちですが『ダメ』です。
ダメな理由は次の記事『C言語 ソースファイルの書き方【どこに何を書くべきかを解説】』で解説しましょう!
ヘッダファイルの定義例と書き順について
師匠!ヘッダファイルの「お手本の書」はありませんか?
一筆一筆それを見ながら練習すれば、わたしも書けるようになると思うのですっ!
それじゃあ、僕が普段書いているヘッダファイルの例を、お手本として見せましょう!
何気に書くべき順番が決まっているので、注意が必要なんです。
具体的なヘッダファイルの定義例を示しましょう。
ヘッダファイルのサンプル定義例
このヘッダファイルの定義例は、私が実際に開発するときの基本フォーマットです。
コメントで各部品の定義場所を明確にし、自分以外がメンテナンスするときでも、記述ルールを守れるようにしてあります。
sub.hのヘッダファイル定義例
#ifndef SUB_H
#define SUB_H
//------------------------------------------------
#include <stdio.h>
//------------------------------------------------
// マクロ定義(Macro definition)
//------------------------------------------------
#define D_SUB_NUM (10)
//------------------------------------------------
// 型定義(Type definition)
//------------------------------------------------
typedef struct
{
long num1;
char moji[D_SUB_NUM];
} S_SUBINFO;
//------------------------------------------------
// プロトタイプ宣言(Prototype declaration)
//------------------------------------------------
int subPrint(S_SUBINFO info);
//------------------------------------------------
#endifヘッダファイルの定義で特に気をつけるべきなのが、「マクロ定義」「型定義」「プロトタイプ宣言」の書き順についてです。
コンパイラはソースコードの先頭から翻訳を行いますが、参照するよりも先に定義が必要となります。
「マクロ定義」「型定義」「プロトタイプ宣言」の書き順がどのように決まるのか、その仕組みを解説していきますよ。
このサンプルを利用しても利用しなくてもいいんです。
自分の中で「これだ!」という基本フォーマットを決めておくと、パターン化ができて作業が速くなります。
「マクロ定義」と「型定義」の依存関係
「構造体定義」の中でよく出てくるのが配列データです。この時、配列要素数を「マクロ定義」で指定することがよくあります。
例を示しましょう。次のように「D_SUB_NUM」マクロ定義を利用して構造体が定義されます。
//------------------------------------------------
// マクロ定義(Macro definition)
//------------------------------------------------
#define D_SUB_NUM (10)
//------------------------------------------------
// 型定義(Type definition)
//------------------------------------------------
typedef struct
{
long num1;
char moji[D_SUB_NUM]; // マクロ定義の参照
} S_SUBINFO;つまり、「マクロ定義」と「型定義」の2つの関係において、「マクロ定義」を先に書く必要があります。
「型定義」と「プロトタイプ宣言」の依存関係
「プロトタイプ宣言」の中では、関数の引数として「構造体」や「列挙型」などのデータ型の変数定義がよく出てきます。
例を示しましょう。次のようにsubPrint関数の引数が構造体の変数で定義されます。
//------------------------------------------------
// 型定義(Type definition)
//------------------------------------------------
typedef struct
{
long num1;
char moji[D_SUB_NUM];
} S_SUBINFO;
//------------------------------------------------
// プロトタイプ宣言(Prototype declaration)
//------------------------------------------------
int subPrint(S_SUBINFO info);つまり、「型定義」と「プロトタイプ宣言」の2つの関係において、「型定義」を先に書く必要があります。
「マクロ定義」「型定義」「プロトタイプ宣言」の書き順まとめ
ここまでの結果をまとめると、次の順で定義を行うのが基本となります。
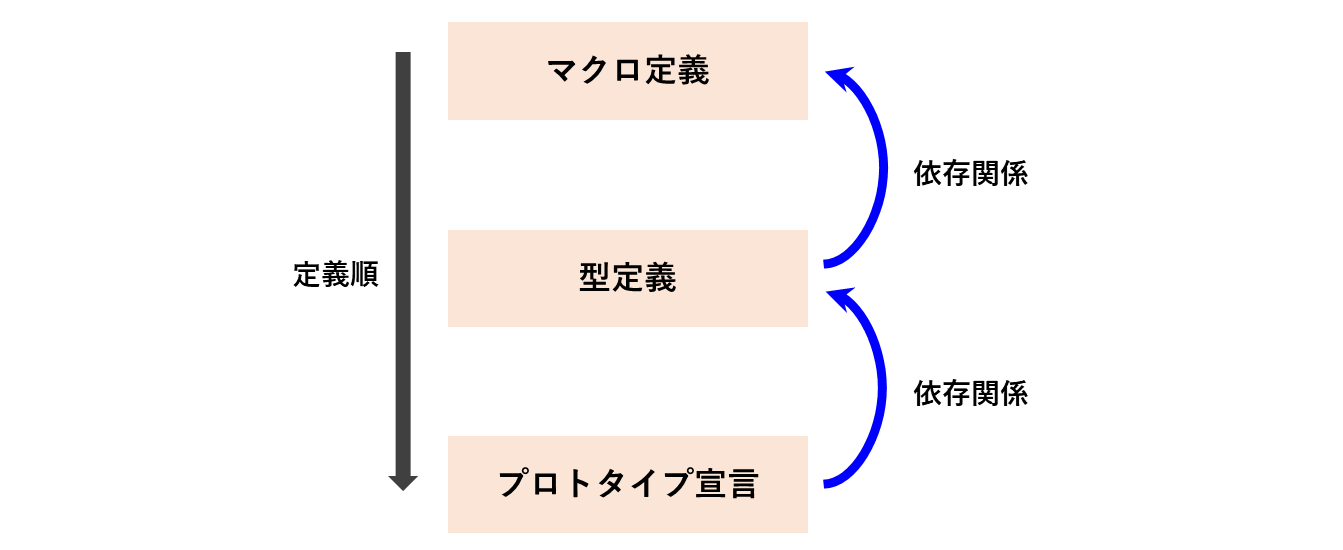
この書き順を守らないとシステム規模が大きくなるにつれ、ビルドエラーが起きやすくなります。
ヘッダファイルの部品には書き順がある!これは大事なことです。
書き順を細かいことと感じるかもしれませんが、こういった知識の積み重ねが、大きなシステムを作り出すための技術なんです。
ヘッダファイルに施す「多重インクルード防止」とは?
ヘッダファイルの部品の中で「多重インクルード防止」なんてものがあります。これはいったい何ですか?
多重インクルード防止というのは、『同一のヘッダファイルを1度だけしかインクルードしない』ようにする仕掛けだよ。
皆さんがこれからヘッダファイルを作るときに、気を付けることがあります。
それは、
『多重インクルード防止の仕掛けを必ず入れること』
です。
この防止策を入れないと、ヘッダファイルを利用する他の方に迷惑を掛けますので、必ず実施してください。
多重インクルード防止の書き方
「多重インクルード防止」とは、次の部品のことを言います。「sub.h」の場合の定義例です。
#ifndef SUB_H
#define SUB_H
// ・・・ヘッダ定義の詳細・・・
#endifプリプロセッサの「条件コンパイル」と「マクロ定義」を利用して書きます。この記述を「多重インクルード防止」と呼びます。
この仕組みを使うことで、対象のヘッダファイルが複数回インクルードされることを防止することができます。
ヘッダファイルには、必ずこの細工を施すことがC言語開発者の暗黙のルールです。どんな効果があるのかを解説しましょう。
プリプロセッサについて詳細を知りたい方は『C言語 プリプロセッサ【絶対知るべき3大機能を順に解説する】』の記事を参照してください。
多重インクルード防止の必要性
ヘッダファイルをインクルードするとは、プリプロセッサによって「ファイルの中身がコピー&ペーストされること」であると説明しました。
この「コピー&ペースト」というものが曲者で、好き勝手にコピペすればよいという単純な話ではないのです。
例えば、次のように同一のヘッダが複数回インクルードされてしまうと、型定義の名称が重複してビルドエラーとなります。
#include "sub.h"
#include "sub.h" // 同名ヘッダを再度インクルード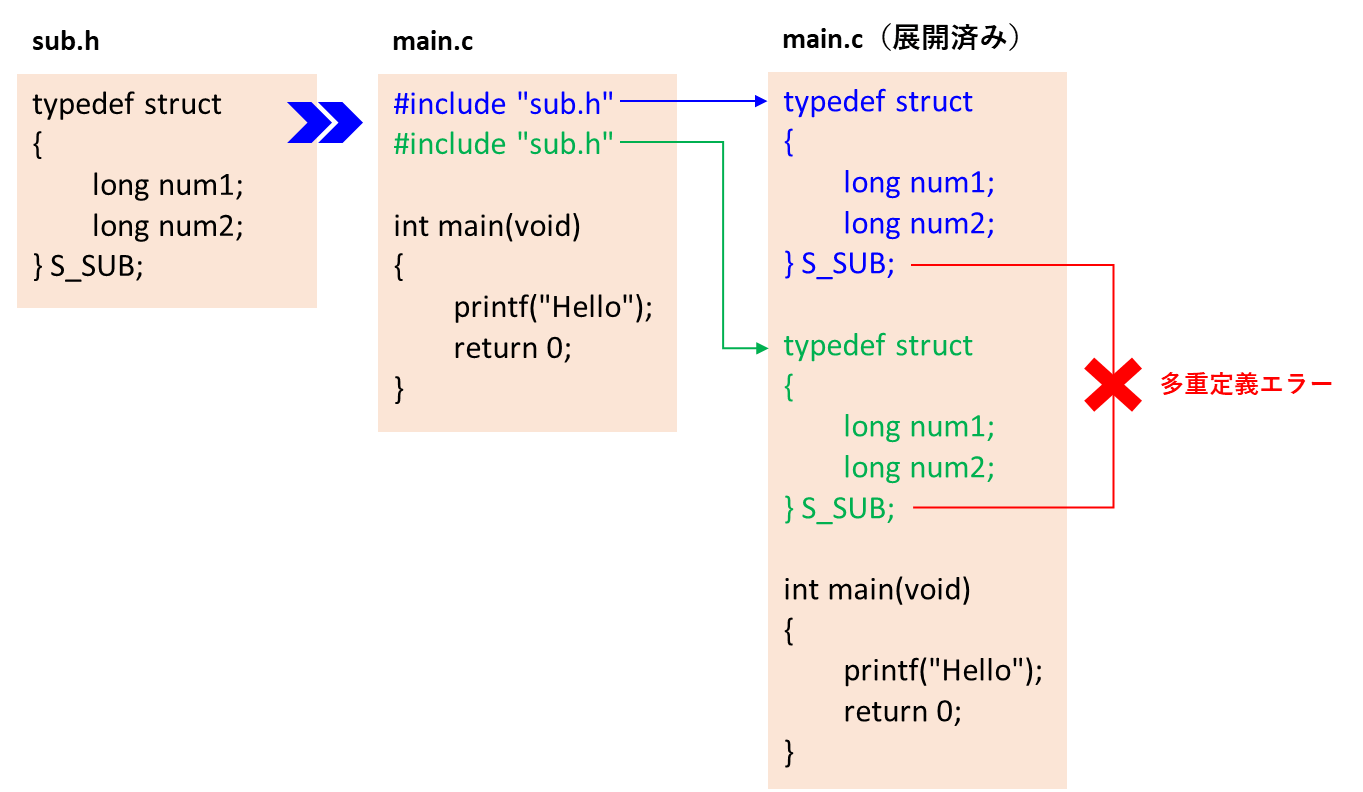
構造体や列挙型といった型定義は、同一ソースファイル上での同名定義は認められていません。
「同じヘッダファイルを繰り返しインクルードしているのはおかしいでしょ」との指摘はごもっともであり、「片方を記述を削除すればいいよね!」と考えるかもしれません。
しかし、その対策はこの問題の本質的な解決にはなりません。
実際の大規模システム開発ではヘッダファイルの数も多く、ソースファイルもヘッダファイル自身も様々なヘッダファイルをインクルードする構成が普通です。
つまり、様々なソースファイルやヘッダファイルが、各自の都合で使いたいヘッダファイルをインクルードするのが当たり前なんです。
そのような状況で、インクルードの最終展開結果として『とあるヘッダファイルが1度しかインクルードされないように調整する』なんてことは現実的にできないのです。
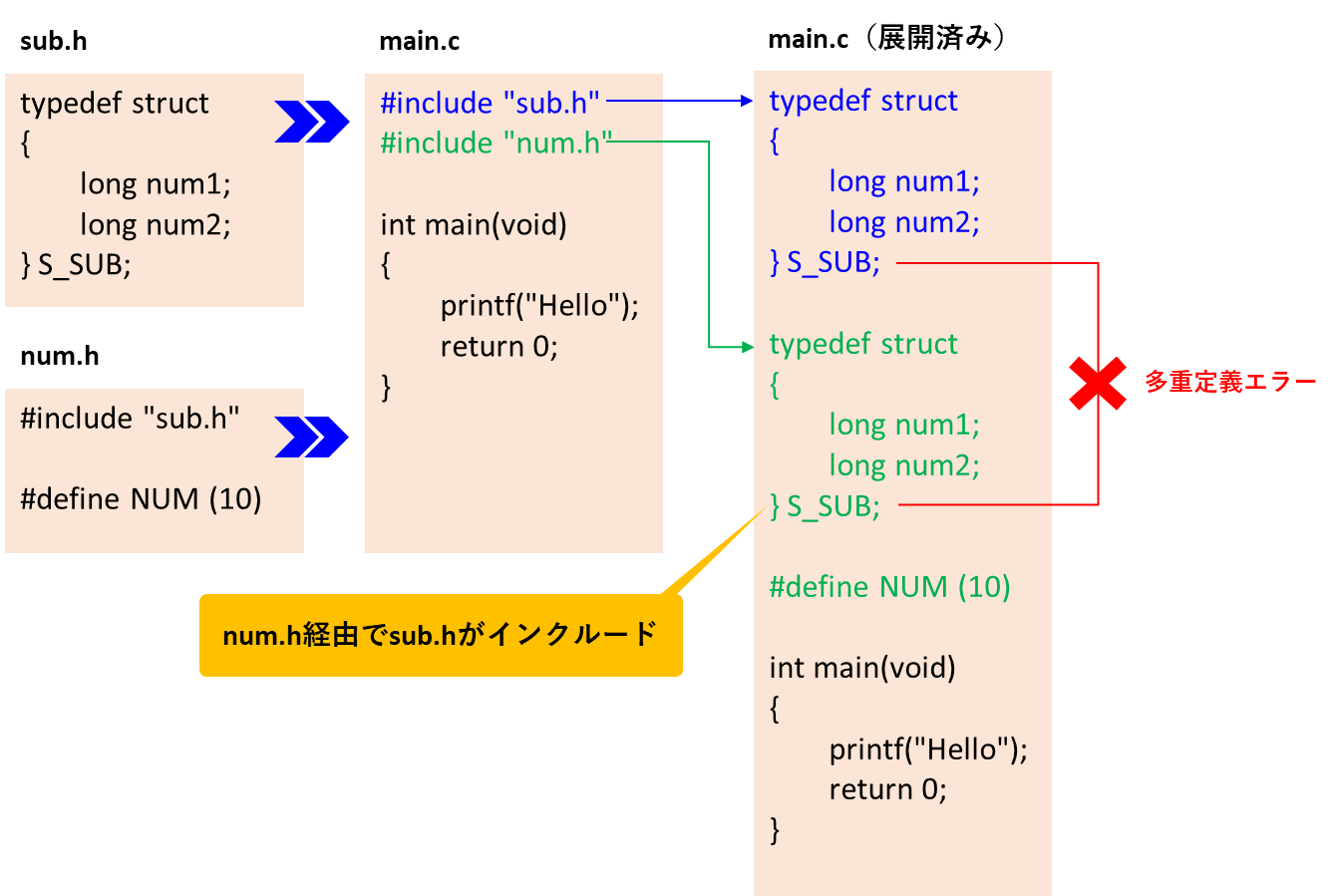
このように意図せず様々なヘッダファイルを通して、とあるヘッダファイルが複数回インクルードされるケースがあります。
そのため、複数回インクルードされることを前提に、ヘッダファイルには多重インクルード防止策を必ず施します。
多重インクルード防止の仕掛けを入れておかないと、ヘッダをインクルードした側のプログラムでビルドエラーが発生します。
多重インクルード防止の仕組みを解説
多重インクルード防止の機構ってどうやって成立しているかわかりますか?
sub.h
#ifndef SUB_H
#define SUB_H
#define D_SUB_NUM (100)
#endifこのファイルを2回インクルードしてみましょう。
#include "sub.h"
#include "sub.h"インクルードとはファイル内容のコピペですので、次のようになります。
#ifndef SUB_H
#define SUB_H
#define D_SUB_NUM (100)
#endif
#ifndef SUB_H
#define SUB_H
#define D_SUB_NUM (100)
#endif明るい行がカット対象の行となります。
2行目の「#define SUB_H」によって、8行目の#ifndefがカット対象となるのがわかりますね。
これが多重インクルード防止の仕掛けの正体です。
「ifdef」機能について詳しく知りたい方は『C言語 ifdef 【プログラムをカットする技術と使い方を紹介】』を参照しておくとよいでしょう。
こうやって考察すると結構シンプルなロジックで多重の読み込みを防止しているのがわかりますね。
「条件コンパイル」と「マクロ定義」は、アイデア次第で非常に強力なカット機構を持っているのです。
ヘッダファイルに書くプロトタイプ宣言の必要性とは
ヘッダファイルの中には、関数のプロトタイプ宣言というものを記述します。
プロトタイプ宣言の役割の詳細に関しては『C言語 プロトタイプ宣言の効果【関数を安全に呼び出す仕組み】』を見ておくとよいでしょう。
次のように、関数の頭の部分だけをセミコロンで閉じたものが「プロトタイプ宣言」です。
// 関数のプロトタイプ宣言
void sub(long num1, double num2);実は、プロトタイプ宣言は皆さんのプログラムミスを検出するための機能なのです。
ヘッダファイルにプロトタイプ宣言を書くことで、次のように関数呼び出しが正当に行われているかをチェックするのです。
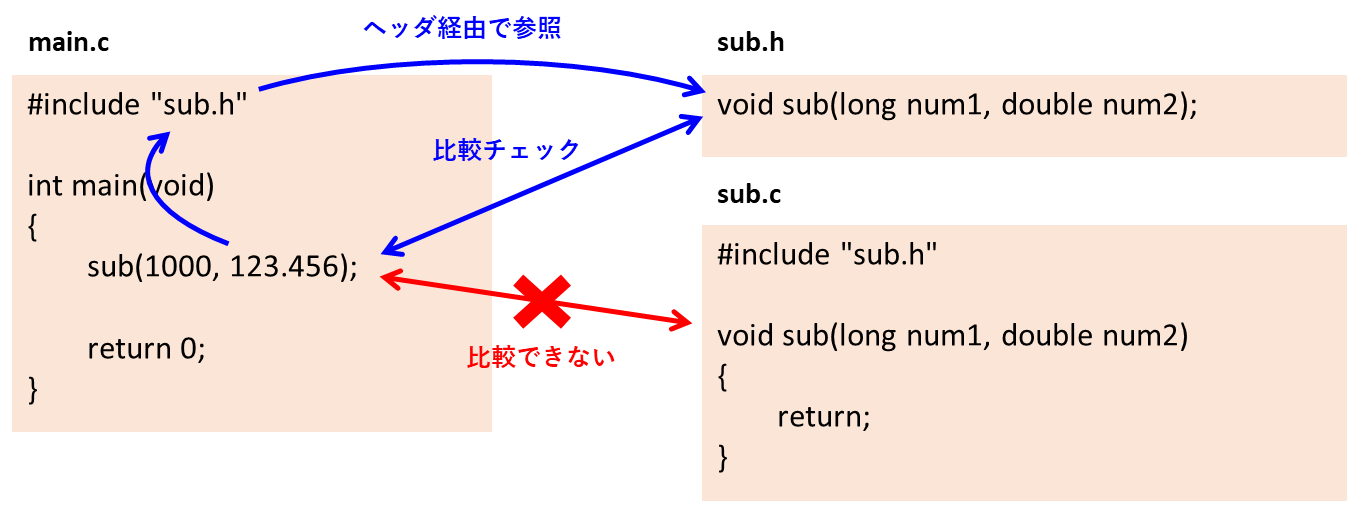
main.cの翻訳をする際にコンパイラがsub.cの関数定義を直接見に行ければよいのですが、コンパイラは翻訳対象のソースファイルしか見ることができません。
つまり、sub.cの関数定義から正解を知ることはできないのです。
ここで登場するのが「プロトタイプ宣言」です。
sub.hにプロトタイプ宣言を記述することで、ヘッダファイルを経由してsub関数の戻り値や引数の構成をmain.cに取り込むのです。
プロトタイプ宣言の基本は、ヘッダファイルへ記述することです。
ヘッダファイルを学んだ後は、ソースファイルに何を書けばよいかを学びましょう!

