







こんにちは、ナナです。
残念なことにC言語は、文字の扱いが非常に苦手な言語です。
そのため、文字の扱いに慣れていないプログラマーが、文字を加工するプログラムを作ると簡単に不具合が発生します。しっかりと「文字」と「文字列」の扱い方をマスターしましょう。
本記事では次の疑問点を解消する内容となっています。
「文字」は、配列との関係性が深い内容です。
配列を知らずにこの記事を読もうとしている方は、まずは『C言語 配列と2次元配列を図解【便利さと特別なルールを解説】』を読んでからの方がよいでしょう。

では、文字の扱い方を学んでいきましょう。
文字はどのようにコンピューターで管理されている?
今日の講義内容はなんですの?文字?あなた、わたくしをバカにしてるんじゃないわよね。文才溢れるわたくしに、何を語ろうというつもりなのかしら?
国語の授業じゃないから言葉としての文字を教えるって内容じゃないよ…。プログラムから文字を扱うための内容だね。
みんなが普段文字を扱うのと同じように、プログラミングの世界でも文字を扱いたいってことがあるんだね。
配列を学んだあとは「文字」の扱いについて学びます。プログラムの中で文字を管理することはよく行われます。
文字は数値で管理されている
コンピュータの世界では、あらゆる情報は数値として管理されています。
それは、「文字」という情報も例外ではありません。
皆さんの目の前に「ABC」という文字が表示されていたとしても、コンピュータの内部では数値として管理されているのです。
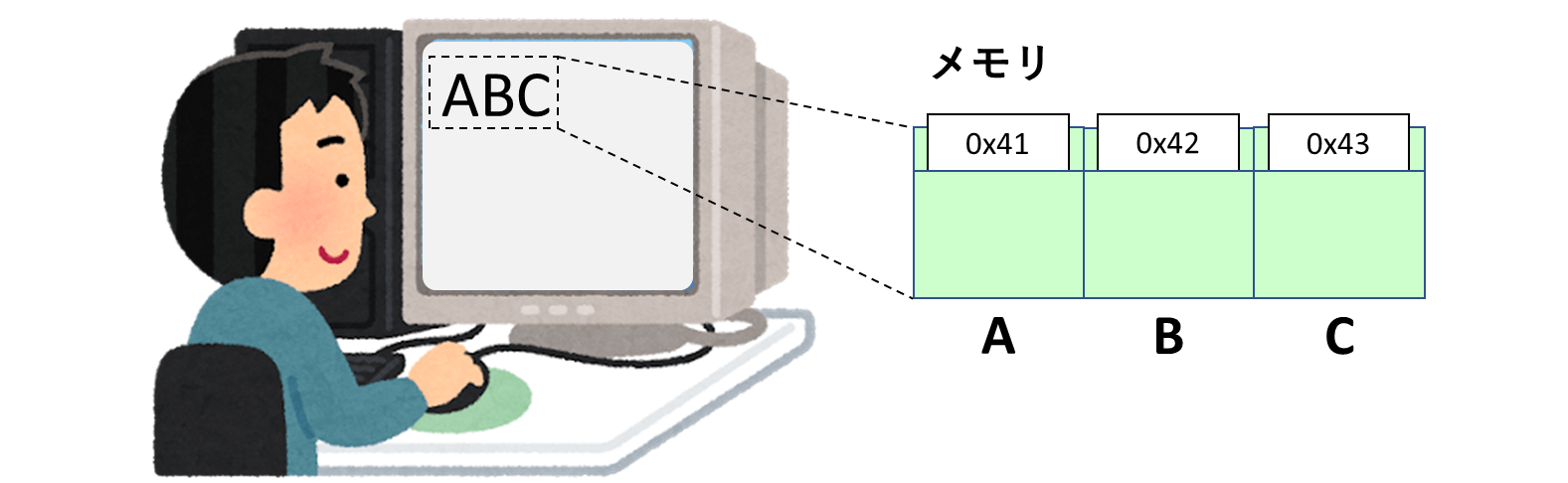
こんなことを実現するためには、1つの「文字」というものに対して、対応する数値を紐付ける必要があります。
「Aという文字には0x41という数値を紐付けよう」というルールがあって初めて成立するのです。
そのルールを「アスキーコード(ASCII)」と呼びます。
アスキーコード一覧
アスキーコード表と呼ばれるのが次の表です。
数が多いですが、これらを数値を覚える必要はありません。大切なのは「文字」というものが、コンピュータの内部では「特定の数値」として管理されているということです。
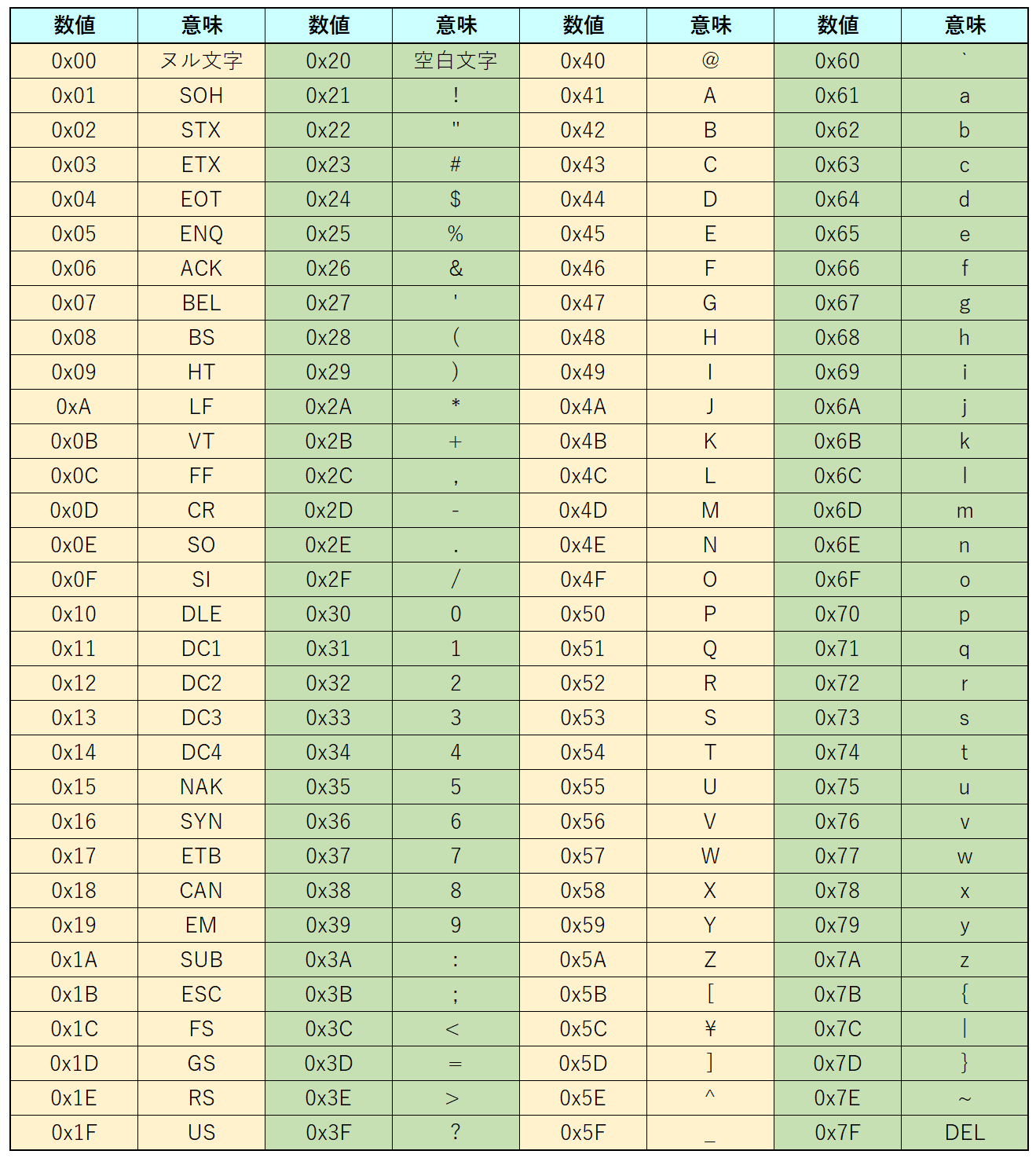
0x00~0x7Fまでの数値が、文字と関連付けてあるのがわかりますね。
文字を管理するプログラム
わたくし、誤解しちゃったわ。プログラムから文字を扱うってことなのね。
プログラミングの世界でも、わたくしの文豪としての才能を開花させてあげるわ。文字の扱い方をお教えなさいっ!
それじゃあ、まずは1つの文字をどのように管理するのかの方法を学んでみよう。小さな一歩だけど、何事も基礎が大事だからね。
C言語のプログラムから文字情報を扱うための方法が用意されています。まずは、1つの文字を扱うルールをマスターしましょう。
文字を管理するデータ型。それが「char型」
C言語では文字を扱うためのデータ型があります。それはchar型です。
char型は-128~127までの数値を管理するためのデータ型でしたが、実は文字を管理するデータ型でもあるのです。
char型とはcharacter(文字)の略であり、もともと文字を管理するために用意された型です。
アスキーコード表の0x00~0x7Fというのは、char型の正値の範囲である0~127と一緒であり、char型と密接に関連しているのがわかります。
文字を使ったプログラム
文字を使ったプログラムを示します。皆さんもこのプログラムを書いて動かしてみてください。
char型の変数mojiに対して、「A」という文字を代入したケース①と、「0x41」という数値を代入したケース②で動作を見るためのプログラムです。
#include <stdio.h>
int main(void)
{
char moji;
// ①:文字としてAを代入
moji = 'A';
printf("%c , 0x%x\n", moji, moji);
// ②:数値の0x41を代入
moji = 0x41;
printf("%c , 0x%x\n", moji, moji);
return 0;
}1つの文字をchar型の変数に代入するためには、①のようにシングルクォーテーションでその文字を括ります。つまり、文字は「’A’」といった形で1文字分を指定します。
「’AB’」のように2文字以上の複数の文字を指定することはできません。
printf関数では%cを使うことで、char型の数値情報をアスキーコードの文字として画面表示をする機能が備わっています。
さあ、動作させると次の結果が表示されたことでしょう。全く同じ結果が表示されていますね。
A , 0x41
A , 0x41つまり、①と②のプログラムは、結果として全く同じ数値を代入しているということです。
このように文字の正体とは数値であり、コンピュータ内部では結局は数値情報として管理されているのです。
シングルクォーテーションは1つの文字をC言語で扱うための記号なんです。「シングルだから1文字」って覚えてくださいね。
慣れない人は複数の文字をシングルクォーテーションで括ってしまうんですが、それは間違いです。警告は出るけど、ビルドエラーにならないから注意してください。
「文字列」:複数の文字を使った表現方法
char型って「文字」のことを意味していたのね。わたくし全然気づかなかったわ。
でも、1文字だけしか扱えないって不便すぎるわよ。わたくしの文才は1文字なんかで表現できるわけないじゃないのっ!
そうだね、1文字だけで文字を扱うことはやっぱり少なくて、複数の文字を管理できる「文字列」という形で扱うのが一般的だね。じゃあ、お望みの文字列を教えちゃうよ!
「文字」が、メモリ上に連続で並んだ情報のことを「文字列」と呼びます。
配列に格納する文字情報
C言語において連続的なデータは、「配列」で管理するのでしたね。
つまり、「文字」を配列として複数管理することで、「文字」は「文字列」に変化するということです。
#include <stdio.h>
int main(void)
{
// 10個分の文字配列を定義
char moji[10];
moji[0] = 'H';
moji[1] = 'E';
moji[2] = 'L';
moji[3] = 'L';
moji[4] = 'O';
moji[5] = '\0';
// HELLOと表示される
printf("%s", moji);
return 0;
}プログラムを動かすと画面に「HELLO」が表示されたことでしょう。
printf関数は%sを利用することで文字列を画面に表示できる機能を持っています。「s」とは「string(文字列)」のことです。
このプログラムではメモリに次のように文字が連続的に格納され文字列として認識されます。
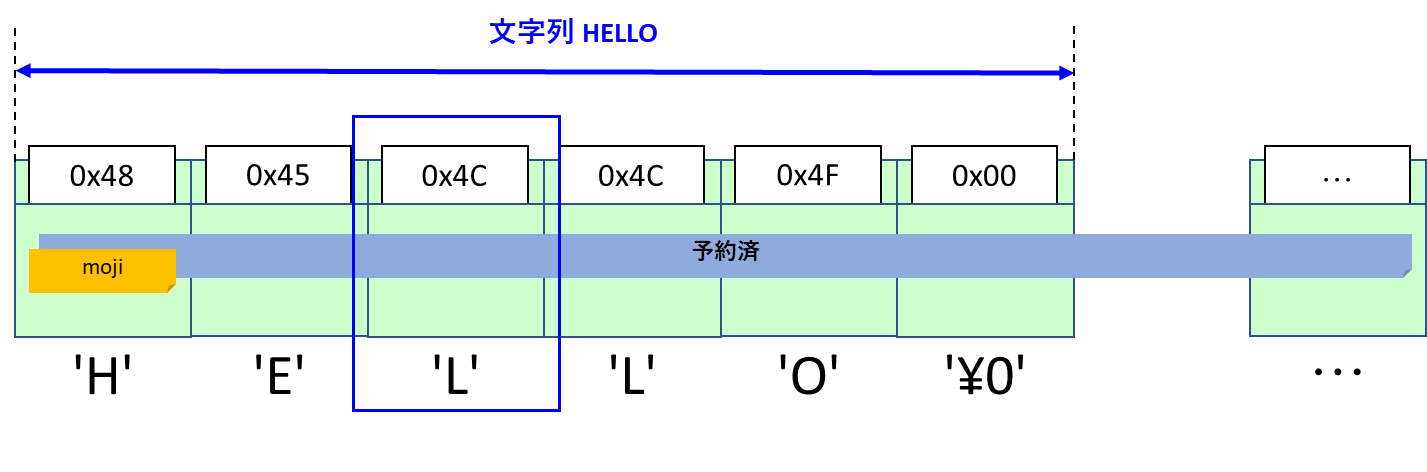
文字列に欠かせない「ヌル文字」って何?
実はC言語で文字列を扱うために、決められたルールがあるんです。
それは、文字列情報の最後に「ヌル文字」を必ず入れてあげることです。ヌル文字は文字列の終端を表す記号なんです。
アスキーコード表の中にある0x00は「ヌル文字」と呼ばれる特殊な文字であり、ヌル文字はプログラムの中では’\0’で表記されます。
char moji = '\0';文字列にはなぜ「ヌル文字」が必要なのか?
メモリ上には、文字列以外にもたくさんの数値が並んでいます。
そのため、コンピュータは「文字」がどこまで続いているのか否かを、区別できる必要があります。
この「文字列の終わり」を示す情報こそが
ヌル文字
なのです。
つまり、皆さんは明示的に「ヌル文字」で文字列の終わりを表明する必要があるのです。
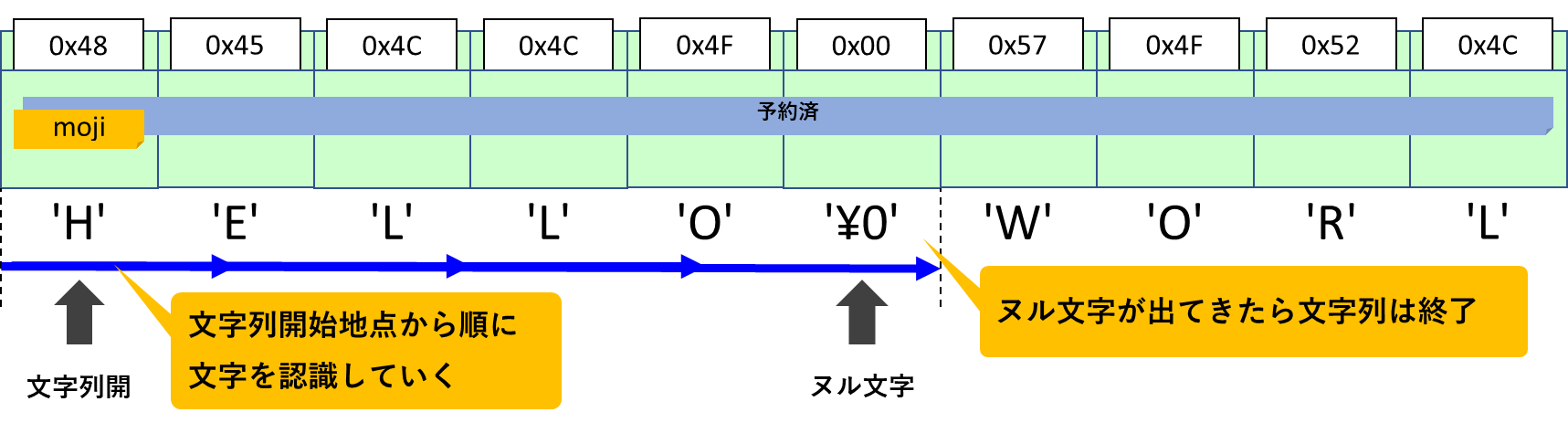
このように、なんらかのデータ終端を明示的に示すものを「番兵」と呼びます。「ヌル文字」は文字列データにおける番兵なのです。

番兵という目印によって「並びの終端はここ!」と示します。
文字列が短くなっても長くなっても、必ず終端は番兵であるヌル文字です。文字列の終わりを知りたければ、先頭から順にヌル文字を見つければよいのです。
文字列情報を皆さんがプログラムから作り出す時は、必ず「ヌル文字」で終わるようにプログラムする必要があります。このルールは文字列を扱う上で、絶対に知っておかなければならないルールです。
もし、ヌル文字を忘れてしまうと、文字列の後ろに続く無関係のメモリ内容を文字として扱おうと頑張ってしまいます。
文字配列の初期化による「文字列」の作り方
「文字列」って文字を配列に並べるってことなのね。
でも、わたくしはたくさんの文字を使って、わたくしのことを世界に広めたいの。自叙伝を書くのに1文字1文字配列に入れてたら疲れるわよっ!
プログラムで語る自叙伝、楽しみだね。そんな君に朗報だよ。文字列は一度に作り出す方法が用意されているよ。これを使って文字列を作ってみるといいよ。
文字列を作るのに、毎回1文字ずつプログラムしていたのでは日が暮れてしまいます。文字列は変数定義と共に一気に作り出すことが可能です。
文字列データの初期化方法:その①
1つ目の方法は次のように、配列の初期化時に文字を1つずつ並べる方法です。
配列の初期化になるため{}を使って初期化することになります。
#include <stdio.h>
int main(void)
{
// {}を使って1文字ずつ配列を初期化
char moji1[10] = {'H','e','l','l','o','\0'};
// Helloと表示
printf("%s\n", moji1);
return 0;
}この方法はシングルクォーテーションを複数並べただけの形であり、文法的には問題ありませんが実践的な書き方ではありません。
文字列データの初期化方法:その②
配列の初期化においてダブルクォーテーションを使い文字列を設定することができます。
この初期化方法においては{}は記述する必要はありません。
#include <stdio.h>
int main(void)
{
// 文字列リテラルを使って一度に初期化
char moji2[] = "World";
// Worldと表示
printf("%s\n", moji2);
return 0;
}ダブルクォーテーションで括った文字列のことを「文字列リテラル」と呼びます。
変数定義と同時に初期化として使ってください。代入ではこの書き方は使えないため注意が必要です。
文字列リテラルの終端には「ヌル文字」が指定されていませんが心配ありません。
文字列リテラルでは、終端にヌル文字を自動的に格納してくれます。また、通常の配列データと同様に配列要素数を省略することも可能です。
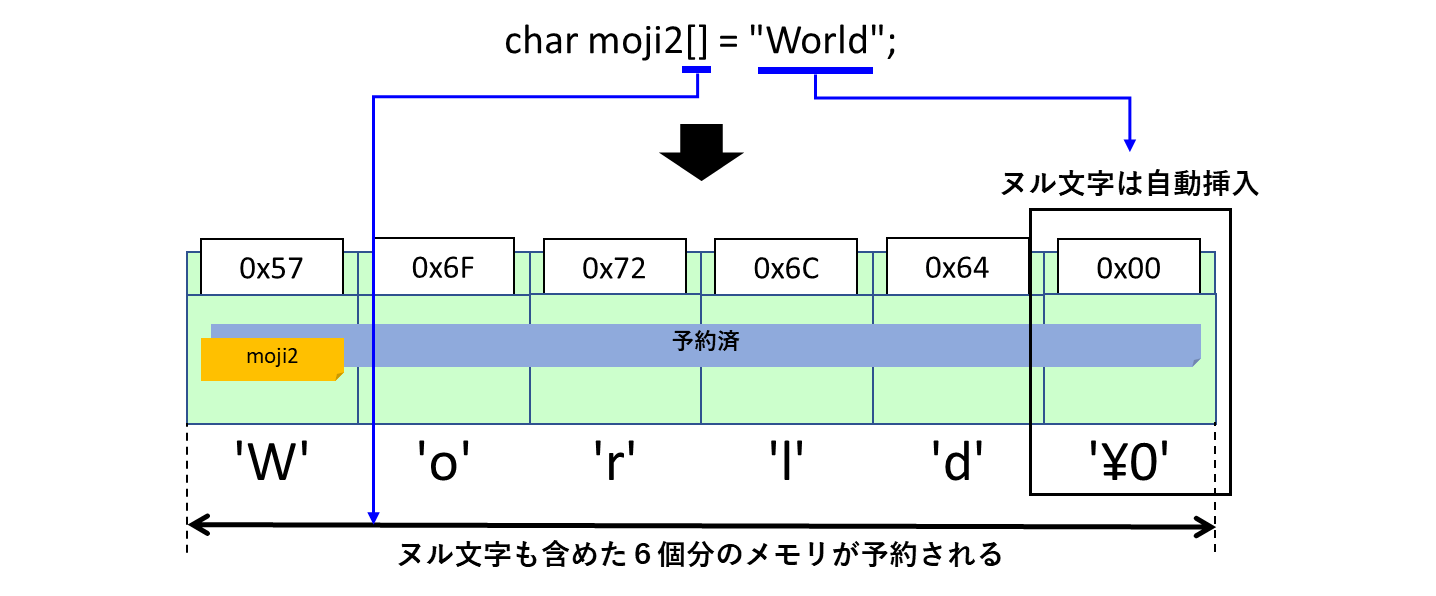
C言語で文字列を扱う時の代表例が、この文字列リテラルを利用した文字情報の設定です。しっかりと書き方をマスターしてください。
標準ライブラリ関数を利用した文字列制御
プログラムから「文字」を扱うって思ったより大変だわ。みんな、こんなことよくやるわね。もっと楽はできないのかしら?
そうだね。C言語で文字を扱うのは結構大変なんだよ。
だから、文字と文字列を扱うための関数がいろいろと用意されているよ。これを使うと、文字に関するプログラムが比較的簡単に作れるようになるんだよ。
文字列を扱うための基礎的な「標準ライブラリ関数」の使い方を学びましょう。
標準ライブラリ関数とは
標準ライブラリ関数とは、
C言語の開発環境で使用できる、あらかじめ用意された関数のこと
です。
皆さんを含め世の中にはたくさんの開発者がいるわけですが、誰しもが求める機能があるわけです。
ここまで皆さんが何度も使ってきた「printf関数」も、標準ライブラリ関数の1つです。
このように誰しもが必要とする機能を各個人でそれぞれ作っていたら大変なため、標準ライブラリ関数という形で誰でも使用することができるようにしているのです。
標準ライブラリ関数には大量の関数が用意されています。本記事では代表的な次のライブラリ関数を紹介しましょう。
| 関数名 | 概要 | 関数仕様 |
|---|---|---|
| memcpy | メモリ内容のコピー | memcpy(コピー先配列, コピー元配列, コピーサイズ); |
| strcpy_s | 文字列のコピー | strcpy_s(コピー先配列, コピー先配列サイズ, コピー元配列); |
| strlen | 文字列の長さを取得 | size_t strlen(文字列配列); |
実際に標準ライブラリ関数を使用したプログラム例を示します。これらの関数を使用するためには#include <string.h>を先頭に追記してください。
実際にこのプログラムをステップ実行で動かすと、標準ライブラリ関数によって文字列情報がどのように扱われるかわかるでしょう。
#include <stdio.h>
// string.hをインクルード
#include <string.h>
int main(void)
{
char moji1[20] = "Hello";
char moji2[10] = {0};
char moji3[20] = "World";
char moji4[10] = {0};
size_t len;
// moji1の文字列の長さ取得
len = strlen(moji1);
// moji1を指定サイズだけmoji2へコピー
memcpy(moji2, moji1, len);
printf("%s\n", moji2);
// moji3の文字列をmoji4にコピー
strcpy_s(moji4, 10, moji3);
printf("%s\n", moji4);
return 0;
}moji2[10]とmoji4[10]という空の配列に”Hello”と”World”の文字をコピーしました。文字列をコピーするという処理もいろいろと書き方があるということです。
Q&A:文字と文字列に関するよくある質問
文字と文字列に関する質問コーナーです。
Q:strlen関数の戻り値の型がsize_tというデータ型になっているが、この型は何?
文字列の長さを調べることができるstrlen関数とやらの戻り値の型がsize_tなんて型になってるわ。こんなデータ型見たことがないわよ。あなたしっかりと説明なさいっ!
size_t型はサイズを管理するためのデータ型だね。標準ライブラリ関数でサイズを示す情報は多くがこのsize_t型として定義されているね。
「size_t型」は文字やメモリのサイズを管理するための型であり、unsigned int型と同じ型になっています。
もちろん「size_t型」の変数を、皆さんが定義することもできますよ。
#include <stdio.h>
#include <string.h>
int main(void)
{
// size_t型の変数定義
size_t len;
len = strlen("World");
return 0;
}strlen関数の戻り値はヌル文字を除いた文字列の長さを取得することができます。
「strlen関数」で取得できる文字列の長さにはヌル文字は含みません。だから、sizeof演算子の結果とは違うことに注意が必要ですよ。
Q:アスキーコードの一覧に日本語がないけど、なんでないの?
よくよく見てみたら、アスキーコードの中には「日本語」が含まれてないじゃないの?わたくしの名前はコンピュータは管理できないってことなの?
「日本語」のような特殊な文字は「マルチバイト文字」と呼ばれる形式で管理されるよ。
アスキーコードってよく見ると128種類の文字しか扱うことができませんね。では、私たちが使っている「日本語」の文字ってどうやって管理されているのでしょうか?
実は、日本語はマルチバイト文字という形で、複数のメモリを使って表現されることになります。
マルチバイト文字を確認するため、次のプログラムを動かしてみましょう。
#include <stdio.h>
int main(void)
{
// 日本語を使った文字列の初期化
char ja_moji[] = "モノづくり";
// マルチバイト文字の表示
printf("%s\n", ja_moji);
// 配列サイズの表示
printf("%d\n", sizeof(ja_moji));
return 0;
}動かすと次のように11バイト文のメモリを使用していることがわかります。
モノづくり
11VisualStudioのデバッガであるローカル機能を使って、「ja_moji配列」の中身の数値をみてあげてください。

日本語の1文字が2バイトのメモリで管理されていることがわかります。これが「マルチバイト文字」です。
世の中には様々な文字が存在するため、このように複数のメモリを使用して表現するのです。
課題:文字と文字列を学べたかを確認しよう
課題1
課題内容
0x20~0x7Eの16進数の値を文字として順番に画面に出力せよ。文字は次のように%cを指定することで表示が可能である。
printf("%c",0x20);出力期待結果
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~main.c
#include <stdio.h>
int main(void)
{
char moji;
for (moji = 0x20 ; moji <= 0x7E ; moji++)
{
printf("%c", moji);
}
return 0;
}アスキーコードの中には、ディスプレイに表示できる文字と、表示できない制御文字と呼ばれるものがあります。0x20~0x7Eが表示できる文字です。
課題2
課題内容
次のプログラムと実行結果を示す。
#include <stdio.h>
int main(void)
{
char moji[] = "Hello World";
//--------------------------
// ↓改変箇所
// ↑
//--------------------------
printf("%s", moji);
return 0;
}Hello Worldmoji配列の中にヌル文字を代入し、表示する文字列を”Hello”のみとするようにプログラムを改変せよ。
出力期待結果
Hellomain.c
#include <stdio.h>
int main(void)
{
char moji[] = "Hello World";
//--------------------------
// ↓改変箇所
moji[5] = '\0';
// ↑
//--------------------------
printf("%s", moji);
return 0;
}Helloの直後の空白文字をヌル文字に変えることで文字列が短くなるってことですね。ヌル文字という番兵の操り方を覚えましょう。
課題3
課題内容
次の変数を定義せよ。

この文字列の長さをstrlen関数を利用し画面に表示せよ。
出力期待結果
11main.c
#include <stdio.h>
#include <string.h>
int main(void)
{
char moji[] = "Hello World";
printf("%d", strlen(moji));
return 0;
}代表的なstrlen関数の使い方を覚えましょう。標準ライブラリ関数の使い方を徐々に学んでいきましょう。
string.hをインクルードするのを忘れずに。
課題4
課題内容
次のプログラムと実行結果を示す。
#include <stdio.h>
#include <string.h>
int main(void)
{
char moji[] = "Hello World";
//--------------------------
// ↓改変箇所
// ↑
//--------------------------
printf("%s", moji);
return 0;
}Hello Worldstrcpy_s関数を使用しmoji配列の中身を”C learning”に変更せよ。
出力期待結果
C learningmain.c
#include <stdio.h>
#include <string.h>
int main(void)
{
char moji[] = "Hello World";
//--------------------------
// ↓改変箇所
strcpy_s(moji, sizeof(moji), "C learning");
// ↑
//--------------------------
printf("%s", moji);
return 0;
}こちらも代表的な文字列コピー用の標準ライブラリ関数ですね。引数構成を知った上で、どのように呼び出すと結果が得られるのかを考えるのです。

