







すでに文字に関する基礎は学びましたが、再度文字列について学ぶ準備が整いました。ポインタを本格的に使用した文字列の制御方法を学びましょう。
ポインタを使った文字列制御
文字列制御を習得するために
文字列を改めてこのタイミングで学ぶのには理由があります。文字列を正しく制御するためには次の技術要素が必要になるからです。
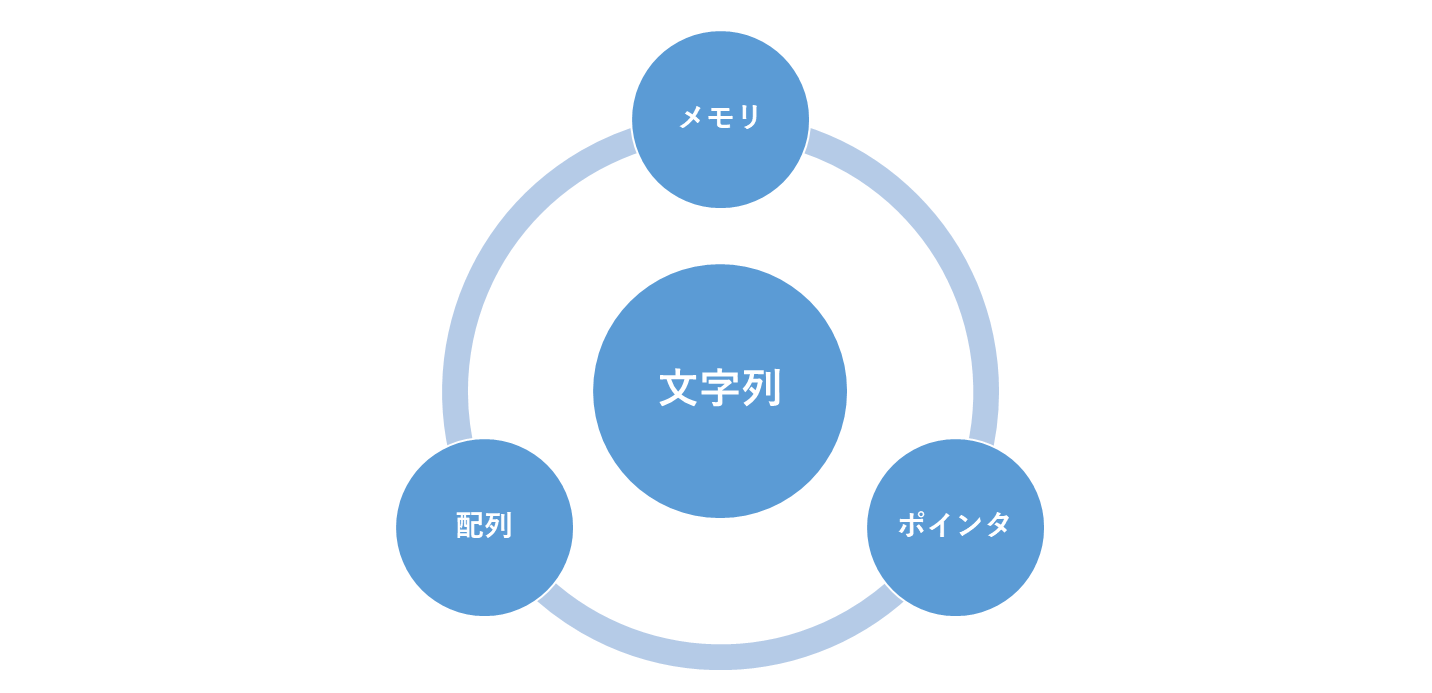
これらを学び終えた今こそが文字列を理解できる準備が整ったことを示しています。
ポインタを使った文字列の参照
配列を使って文字列を管理する方法はすでに学びました。ここではポインタを使った文字列の管理方法を習得します。
配列の初期化ではダブルクォーテーションで括った文字列リテラルを初期値として与えられることは知っていますね。実は文字列リテラルはポインタ変数へも初期化・代入することが可能です。
#include <stdio.h>
int main(void)
{
// 文字列リテラルを配列の初期値へ
char moji[] = "Hello";
// 文字列リテラルをポインタ変数へ設定
char * pmoji = "World";
printf("%s\n", moji);
printf("%s\n", pmoji);
return 0;
}結果は次のものです。
Hello
World一見同じように見えるこの2つの文字列管理方法ですがメモリ上での管理は全く異なっています。それぞれを図でイメージ化してみましょう。
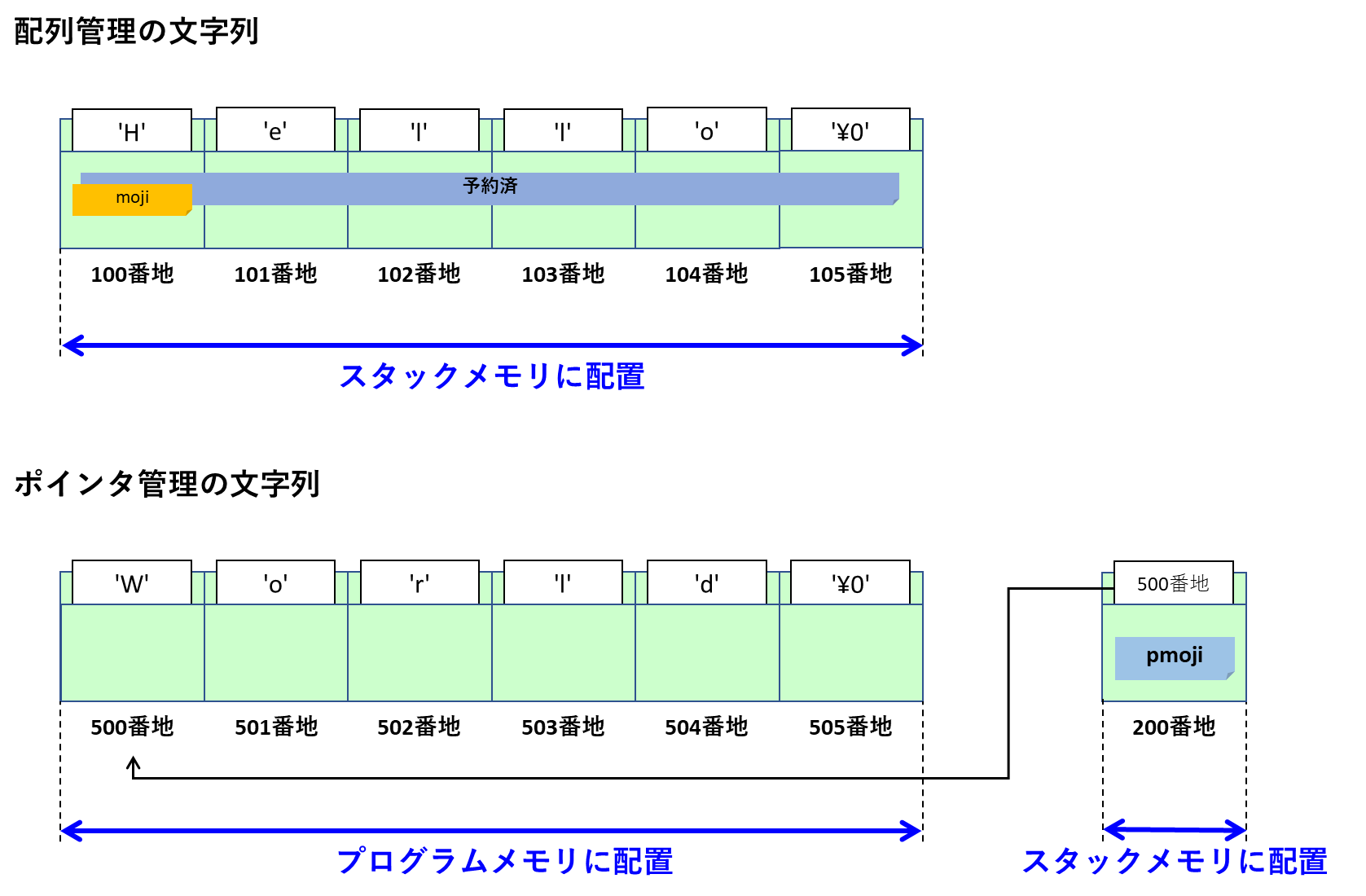
次のようなポインタ変数に対する文字列リテラルの設定は、文字列メモリへの番地設定として解釈されます。
// pmoji --> "World"
char * pmoji = "World";文字列リテラルはプログラムメモリに配置
注意すべきことは、文字列リテラルはプログラムメモリに配置されることです。ポインタ変数pmojiが指し示している先はプログラムメモリになります。
プログラムメモリに関してはメモリの章で学びました。思い出してください、プログラムメモリは関数や定数といった実行中に値の変わらないRead専用の情報が配置されるメモリでした。つまり、このポインタ変数から文字列データの書き換えはやってはならないということです。
#include <stdio.h>
int main(void)
{
// 配列
char moji[] = "Hello";
// ポインタ
char * pmoji = "World";
// 配列はスタックメモリに確保
// 書き換えOK
moji[0] = 'A';
// ポインタの参照先はプログラムメモリ
// 書き換えNG
pmoji[0] = 'B';
return 0;
}このプログラムを動かすと’B’の書き込み部分で実行時エラーが発生します。これはあくまでの一つの例でしかありませんが、文字列制御というのはちょっとした知識のなさが問題を発生させます。C言語において文字列制御は油断ならない処理なのです。
文字列制御を簡単だと思っているうちは素人C言語プログラマー!
文字列・メモリ制御ライブラリから考察するポインタの使い方
文字列初級編にて少しだけ触れた文字列制御ライブラリを深堀りしましょう。文字列の制御方法を学ぶのであれば、文字列制御ライブラリを考察するのが近道です。本章では文字列制御ライブラリを利用する側ではなく、作る側の視点から考察します。
ライブラリ関数の紹介
文字列とメモリの代表的な制御ライブラリ関数を紹介します。
文字列初級編では関数仕様を明確にしていませんでしたが、実際の関数の引数を見るといたるところにポインタが登場しているのがわかります。
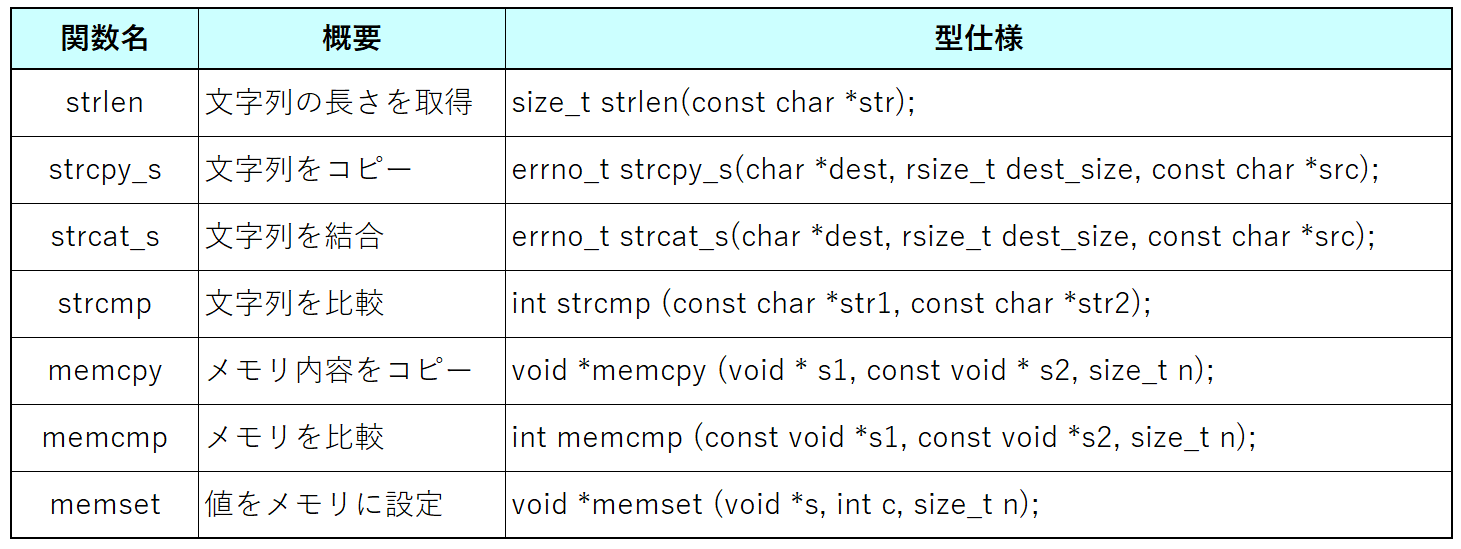
この理由はお判りでしょう。文字列は配列で管理されるデータであり、配列を関数の引数で渡すとポインタになるのでした。つまり、文字列を関数で加工するということはポインタによる制御が必須となるということです。
strlen関数(string length)
strlen関数は文字列の長さを戻り値で取得するためのライブラリ関数です。ヌル文字は長さに含めません。引数として文字列へのポインタを渡す必要があります。
size_t strlen(const char *str);皆さんであればこのstrlen関数をどのように作成しますか?この先の答えを見る前に自分でこの関数を作ってみましょう。関数仕様から関数の作りをイメージできる力は大切な開発スキルです。
次のプログラムはstrlen関数のプログラム例です。皆さんが作成したプログラムと違いはあるでしょうか。
size_t strlen(const char * str)
{
size_t len = 0;
// ヌル文字まで繰り返し
while (*str != '\0')
{
len++; // 長さをカウント
str++; // 照準を横へ移動
}
return len;
}ループ方法
文字列操作では配列データを順に参照するため繰り返し文が出てきます。for文よりもwhile文が使用されることが多いです。それは文字列の長さがわからないため、事前にループ回数を決めることができないからです。本例ではヌル文字が見つかるまでの間は繰り返しています。
引数のconstポインタ
strlen関数の引数をよく見るとconstが付与されています。
size_t strlen(const char * str);constは変数を定数化するものでしたね。ポインタ変数にこのようにconstを付与するとポインタ変数から参照先メモリの書き換えができなくなります。つまり、読み取り専用のポインタになるということです。
strlen関数はその特性から引数で渡された文字列を変更することはありません。このようにconstを付与しておくことで「この引数の文字列は変更されることはないですよ」と呼び出し側に対して明示しているのです。
strcpy_s関数(string copy secure)
strcpy関数は文字列を別の配列へコピーするための関数です。_sは安全性強化用に作られた関数であることを示します。第1引数にコピー先配列、第2引数にコピー先配列要素数、第3引数にコピー元文字列を指定します。
errno_t strcpy_s(char *dest, rsize_t dest_size, const char *src);この関数も同じようにどのように実装するか考えてみましょう。strlen関数ほど簡単ではなさそうですね。

次のプログラムが実装例です。
errno_t strcpy_s(char *dest, rsize_t dest_size, const char *src)
{
//ヌル文字を含めた長さ取得
rsize_t len = strlen(src) + 1;
rsize_t i;
// コピー先配列サイズ確認
if (dest_size < len)
{
return -1;
}
// 文字列コピー
for (i=0 ; i< len ; i++)
{
dest[i] = src[i];
}
return 0;
}コピー先サイズの確認用に先にstrlen関数で文字列サイズをチェックしています。ヌル文字もコピー対象になるため+1しているのがポイントですね。今回はコピーサイズを事前に調べたため、for文によりヌル文字も含めてコピーしてみました。
strcat_s関数(string concatenate secure)
strcat関数は文字列を結合する関数です。猫のcatではなく結合のconcatenateの略です。
第1引数に結合先の文字配列、第2引数に配列サイズ、第3引数に結合したい文字列です。呼び出す際の注意点として、第1引数には第3引数が結合されるため、結合後の文字列サイズが収納できるサイズが確保されていなければなりません。
errno_t strcat_s(char *dest, rsize_t dest_size, const char *src);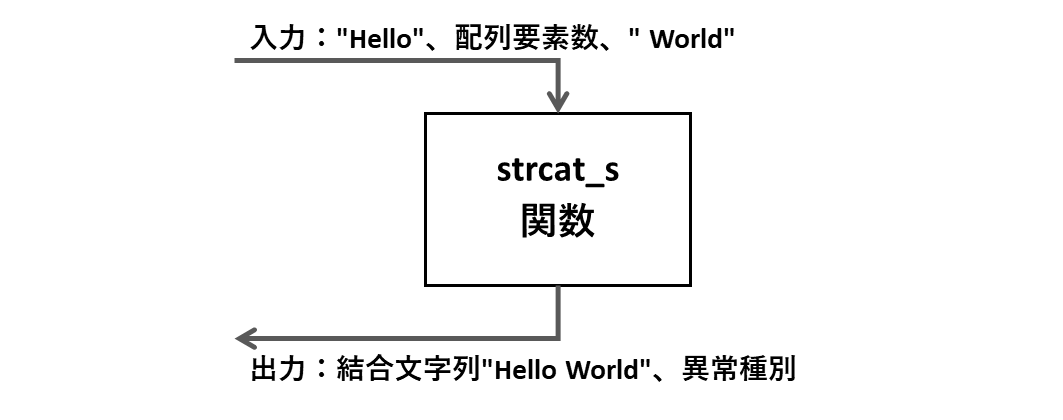
この関数はどうでしょう、作成できたでしょうか。だんだん処理が複雑になってきましたね。
errno_t strcat_s(char *dest, rsize_t dest_size, const char *src)
{
//ヌル文字を含めた長さ取得
rsize_t len = strlen(dest) + strlen(src) + 1;
// 配列サイズ確認
if (dest_size < len)
{
return -1;
}
// 結合前終端までdestポインタを移動
while (*dest != '\0')
{
dest++;
}
// 結合文字を順次収納
while (*src != '\0')
{
*dest = *src;
dest++;
src++;
}
// 終端文字を格納
*dest = '\0';
return 0;
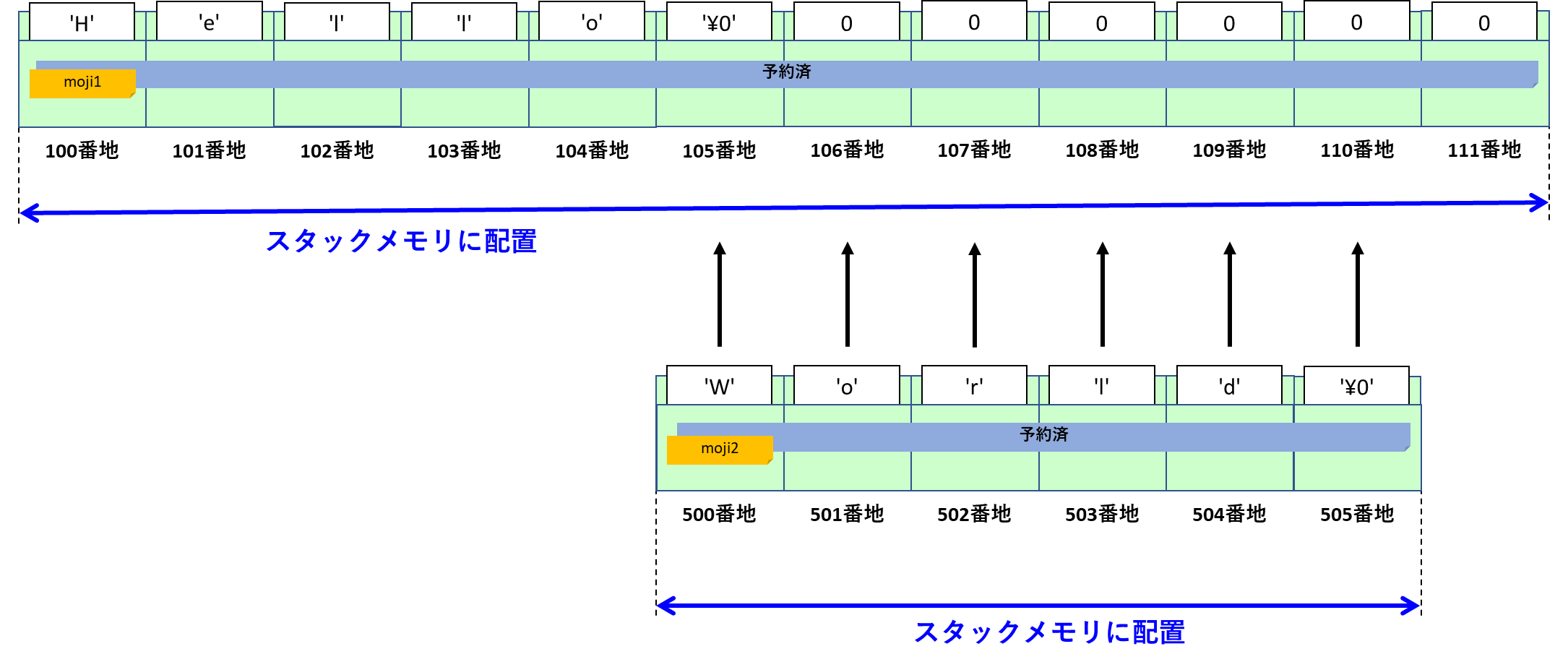
}strcat関数を呼び出すときは次のような形になるのですが、第1引数の配列は余裕を持たせた配列サイズで確保する必要があります。
int main(void)
{
// 結合後の文字も入るサイズを指定必要
char moji1[100] = "Hello";
char moji2[] = "World";
// "Hello" + "World"
strcat_s(moji1, 100, moji2);
return 0;
}
呼び出すときのもう一つの注意点です。第1引数には文字列リテラルを直接指定することはできません。第3引数には指定することができます。
// 呼び出しNG
strcat_s("Hello", 100, moji2);
// 呼び出しOK
strcat_s(moji1, 100, "World");本章をよく学んだ人はお判りでしょう。文字列リテラルはプログラムメモリに配置されるのでした。第1引数に指定するとプログラムメモリ上の”Hello”の後に文字列を書き込もうとしてしまうからですね。
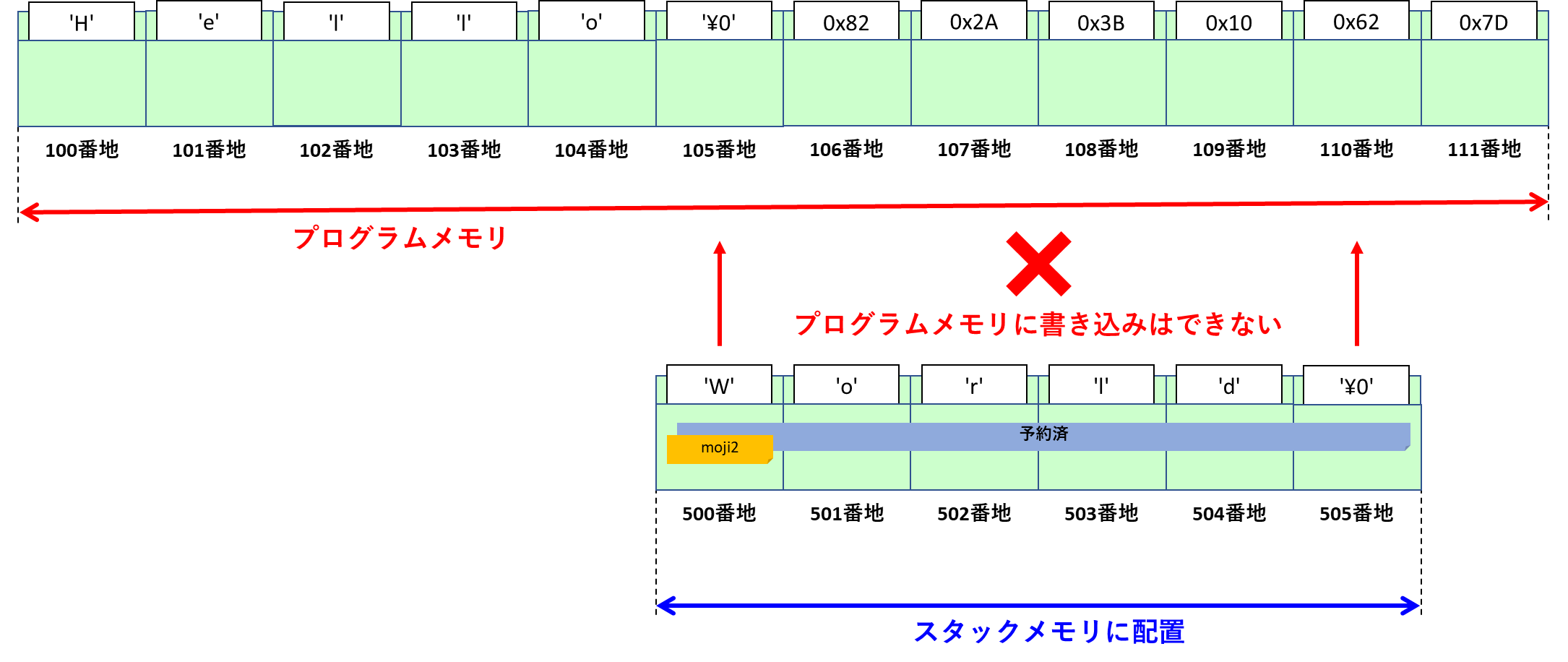
このように文字列制御ではこの文字列が「スタックメモリに配置されている」「プログラムメモリに配置されている」といったメモリを常にイメージできる力が必要です。
文字列制御はメモリ・配列・ポインタの3つの機能の複合技である!
memcpy関数(memory copy)
str系関数はヌル文字を意識した 文字列制御に特化したものでしたが、mem系関数は文字とは関係なく、メモリデータに関する制御を行うためのライブラリ関数です。代表例としてmemcpy関数を学びましょう。
memcpyはその名からわかるようにメモリデータをコピーするための関数です。第1引数にコピー先メモリ、第2引数にコピー元メモリ、第3引数にコピーサイズを指定します。
void *memcpy (void * s1, const void * s2, size_t n);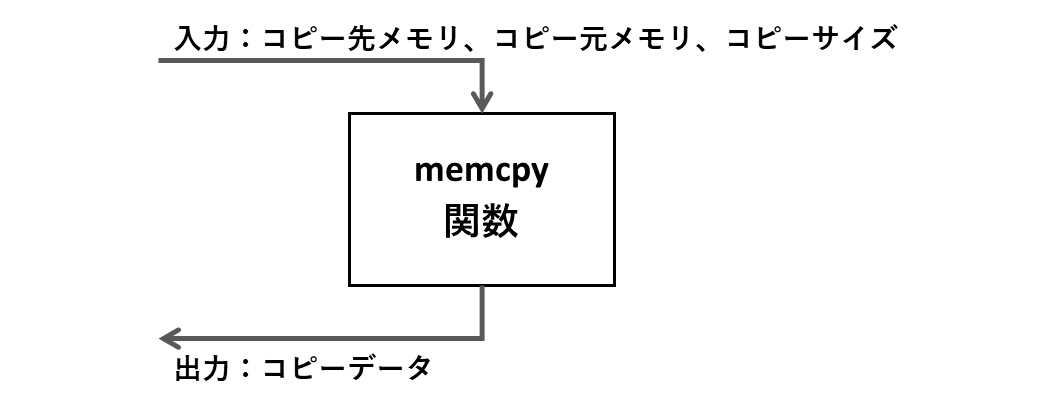
皆さんこの関数を自分で作ることができますか?引数が特殊なデータ型になっていることに気づくことでしょう。void型ポインタをいったいどのように使うのかわかるでしょうか。
では、回答例を紹介しましょう。
void *memcpy(void * s1, const void * s2, size_t n)
{
// s1をcharポインタ型へ変換
char * dst = (char *)s1;
// s2をcharポインタ型へ変換
char * src = (char *)s2;
size_t i;
// 指定サイズのメモリコピー
for (i=0 ; i < n; i++)
{
dst[i] = src[i];
}
return s1;
}void型ポインタの引数
ポインタ中級編で紹介したvoid型ポインタがここで登場しました。void型ポインタの使用シーンはいくつかありますが、memcpy関数では「様々なポインタ型の番地を受け入れたい」シーンとして利用しています。
memcpyに求められるサービスはメモリ内容をそっくりそのままコピーすることです。つまり、コピー元とコピー先のデータ型は関係なくByte単位でデータコピーをすることが仕事です。
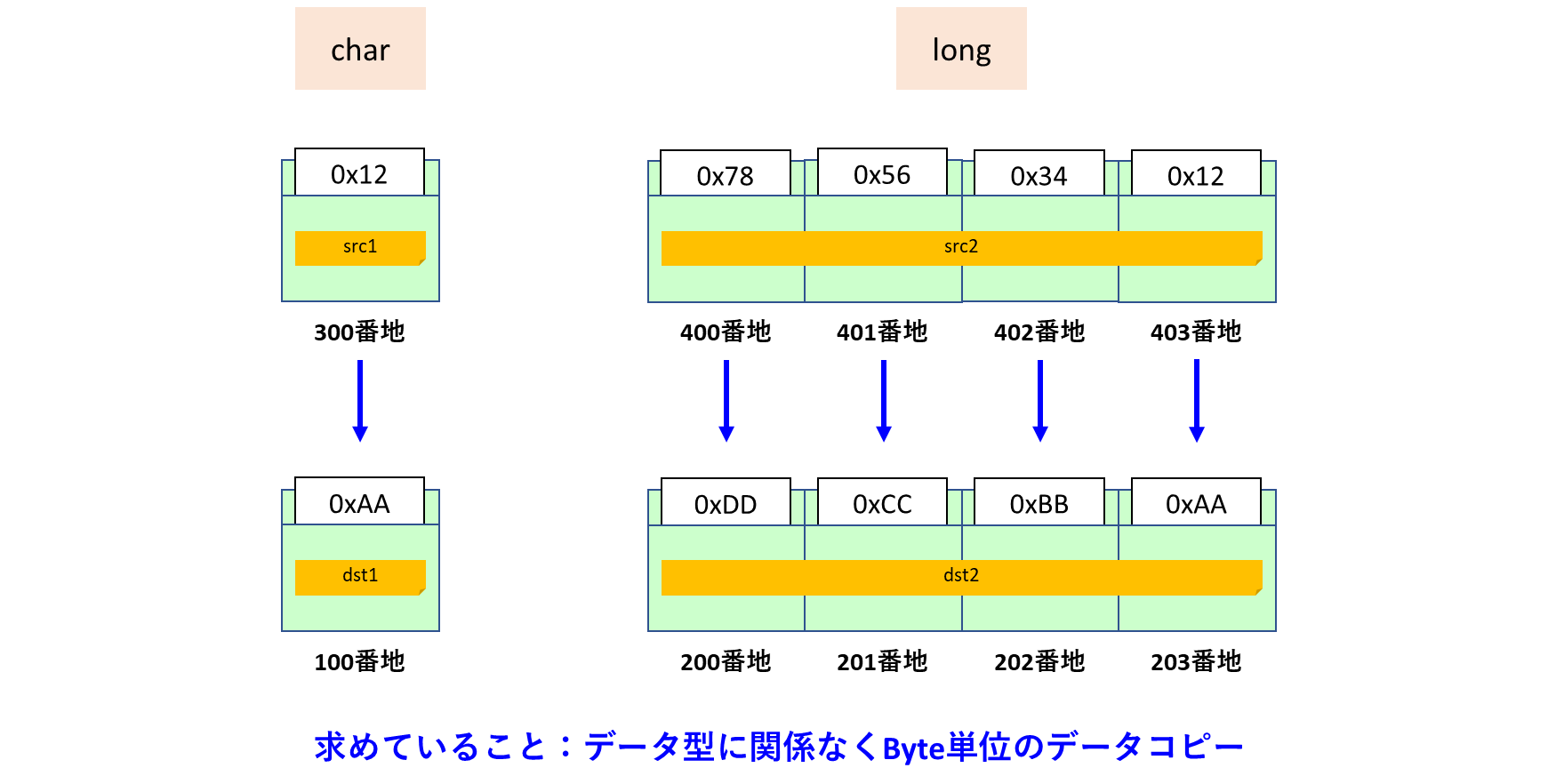
memcpy関数を使用したプログラム例と実行結果は次のようになります。
#include <stdio.h>
#include <string.h>
int main(void)
{
// 1Byte
char src1 = 0x12;
char dst1 = 0xAA;
// 4Byte
long src2 = 0x12345678;
long dst2 = 0xAABBCCDD;
memcpy(&dst1, &src1, sizeof(char));
memcpy(&dst2, &src2, sizeof(long));
printf("0x%x\n", dst1);
printf("0x%x\n", dst2);
return 0;
}0x12
0x12345678これを踏まえたうえで、なぜ引数がvoid型ポインタなのかわかりましたか?
もしもvoid型ポインタというものが存在しない場合、char*型とlong*型で関数を分けなくてはなりません。同一の関数名を定義することもできないため、例えば次のようになるわけです。
// char型版のメモリコピー関数
char *memcpy_char(char * s1, const char * s2, size_t n);
// long型版のメモリコピー関数
long *memcpy_long(long * s1, const long * s2, size_t n);データ型はint型やfloat型など限られていると思いがちですが、C言語には構造体という無限の型定義パターンを作り出す仕組みがあります。つまり、データ型毎にコピー関数を作っていたら切りがないのです。
ここで登場するのがvoid型ポインタです。void型ポインタはあらゆるポインタ型を受け入れることができます。こうすることで参照先データ型に依存しない唯一のmemcpy関数が存在できるのです。
void型ポインタのキャスト
void型ポインタの欠点はメモリアクセスができないことです。参照先のデータ型がわからないのですからアクセスできません。これを解決する方法がキャストです。キャストを使い、型のあるポインタ型への変換を行うことでメモリアクセスを可能にします。
// s1をcharポインタ型へ変換
char * dst = (char *)s1;
// s2をcharポインタ型へ変換
char * src = (char *)s2;このようにchar*型へ明示的キャストを使って型変換を行います。これによりchar型データへのポインタになりました。memcpy関数は1Byte単位でのメモリコピーですからchar型でメモリアクセスができれば十分役割を果たすことができます。
void型ポインタからメモリアクセスが必要であれば明示的なキャストを行え!
Q&A:ポインタを使った文字列制御に関するよくある質問
もともとはstrcpy関数こそが最初に存在したライブラリ関数です。この関数の安全性を向上させるためにstrcpy_s関数へ進化したといえるでしょう。
char * strcpy(char *dest, const char *src);
errno_t strcpy_s(char *dest, rsize_t dest_size, const char *src);この2つの大きな違いは、第2引数でコピー先配列のサイズを渡すように変化したことです。strcpy関数は文字列をコピーする関数ですが、コピー先のメモリサイズが万が一足りなかったときにオーバーランをしてしまう危険性があります。
この問題を解決するためにstrcpy_s関数ではコピー先の配列サイズによりオーバーランを防止できるように進化したのです。
文字列制御用の関数を見ると確かに配列サイズを渡していないものがあります。それは文字列というものがヌル文字の終端で終わることが約束されているからです。
文字列制御をする関数では文字列のサイズをヌル文字を見つけることで知ることができます。そのため、わざわざ配列サイズを引数でもらう必要がないのですね。
課題:ポインタを使った文字列制御が学べたかを確認しよう
もしも、プログラムが上手く動かなくて困ったときは、答えを見るのではなく「デバッガ」の使い方を学びましょう。
この記事を見ると問題の解決技術が身に付きます。困ったときのオススメ記事です!

課題1
課題内容
次の関数を定義せよ。

次のプログラムに上記関数を追加し、出力期待結果が表示されることを確認せよ。
main.c
#include <stdio.h>
int main(void)
{
char sentence[] = "I'm studying programming at a manufacturing C language school.";
char moji;
int count;
moji = 'a';
count = countCharacter(sentence, moji);
printf("文字:%c 個数:%d\n", moji, count);
moji = 'm';
count = countCharacter(sentence, moji);
printf("文字:%c 個数:%d\n", moji, count);
return 0;
}出力期待結果
文字:a 個数:7
文字:m 個数:4main.c
#include <stdio.h>
#include <string.h>
int countCharacter(char * str, char moji)
{
int count = 0;
size_t i;
if (str == NULL)
{
return -1;
}
// 文字列全体を順に参照
for (i = 0; i < strlen(str); i++)
{
// 一致文字をカウント
if (str[i] == moji)
{
count++;
}
}
return count;
}
int main(void)
{
char sentence[] = "I'm studying programming at a manufacturing C language school.";
char moji;
int count;
moji = 'a';
count = countCharacter(sentence, moji);
printf("文字:%c 個数:%d\n", moji, count);
moji = 'm';
count = countCharacter(sentence, moji);
printf("文字:%c 個数:%d\n", moji, count);
return 0;
}課題2
課題内容
次の関数を定義せよ。処理はアスキーコード表を上手に利用するとよい。

次のプログラムに上記関数を追加し、出力期待結果が表示されることを確認せよ。
main.c
#include <stdio.h>
int main(void)
{
char moji[] = "Hello World 2nd!";
// 文字列を大文字に変換
toUpper(moji);
// 文字列表示
printf("%s\n", moji);
return 0;
}出力期待結果
HELLO WORLD 2ND!main.c
#include <stdio.h>
#include <string.h>
int toUpper(char * str)
{
size_t i;
if (str == NULL)
{
return -1;
}
for (i = 0 ; i < strlen(str) ; i++)
{
// 英小文字判定
if (str[i] >= 'a' && str[i] <= 'z')
{
// 英小文字と英大文字の差分を引く
str[i] -= 'a' - 'A';
}
}
return 0;
}
int main(void)
{
char moji[] = "Hello World 2nd!";
// 文字列を大文字に変換
toUpper(moji);
// 文字列表示
printf("%s\n", moji);
return 0;
}アスキーコード表の英小文字と英大文字の関係性を利用している。
課題3
課題内容
次の関数を定義せよ。

次のプログラムに上記関数を追加し、出力期待結果が表示されることを確認せよ。
main.c
#include <stdio.h>
int main(void)
{
char moji[] = "Good Evening!";
reverse(moji);
printf("%s\n", moji);
return 0;
}出力期待結果
!gninevE dooGmain.c
#include <stdio.h>
#include <string.h>
int reverse(char * str)
{
char * pEnd = str;
char tmp;
size_t i;
// 文字列終端へのポインタ取得
for (i = 0 ; i < strlen(str) - 1 ; i++)
{
pEnd++;
}
// 前後を入れ替える
while (str < pEnd)
{
tmp = *str;
*str = *pEnd;
*pEnd = tmp;
str++;
pEnd--;
}
return 0;
}
int main(void)
{
char moji[] = "Good Evening!";
reverse(moji);
printf("%s\n", moji);
return 0;
}文字列先頭と文字列後尾のポインタを用意し、順番に入れ替えている。

