







こんにちは、ナナです。
プログラミングの世界では比較的登場する言葉なのですが、『エンディアン』という言葉を初めて知る方も多いことでしょう。
『エンディアン』とは、とある数をメモリにどのように保管するかを決めるルールです。とあるシーンにおいて、この知識が必要となります。
本記事では次の疑問点を解消する内容となっています。
では、エンディアンとは何かを学んでいきましょう。
エンディアンとは何か?
押忍!今日の講義は「エンディアン」っすか…。はいっ、知らないっす。聞いたこともないっす。今回は素直に講義を聞くっすよ!
そうだね。聞いたことないよね。覚えづらい言葉だけど、プログラミングの世界ではよく取り上げられるから、しっかり学んでいこうね。
『エンディアン』とは、2バイト以上で表現される数値の、メモリへの格納方式のことを示します。
例えば、次のようにshort型変数に「0x1234」という2バイトの数値を格納したとします。
short num = 0x1234;「0x1234」という数値は合計2バイトのメモリに格納することになりますが、メモリは1バイト単位で存在するため、分割して保管することになります。
この時に問題となるのが、数をどのように保管するかなのです。

どっちのメモリに「0x12」を保管するのか?これがエンディアン問題なのです。
エンディアンの種類
押忍!こんなの順番に数を置けばいいっすよ。「0x12」と「0x34」を順番に並べれば完了っす。できたっす。置く順番なんて、これ以外ないっすよ!

確かに人が数を置こうとすると、この置き方が自然だよね。
でもね、コンピュータの世界では、別の保管方法もあるんだよね。どんな保管方法かを学んでいこう!
エンディアンには2種類の方式しかありません。
エンディアンには2つの方式しかありません。覚えるだけなら簡単です!
ビッグエンディアン方式の特徴
「ビッグエンディアン」は人にとって自然に見える形式の格納方式です。
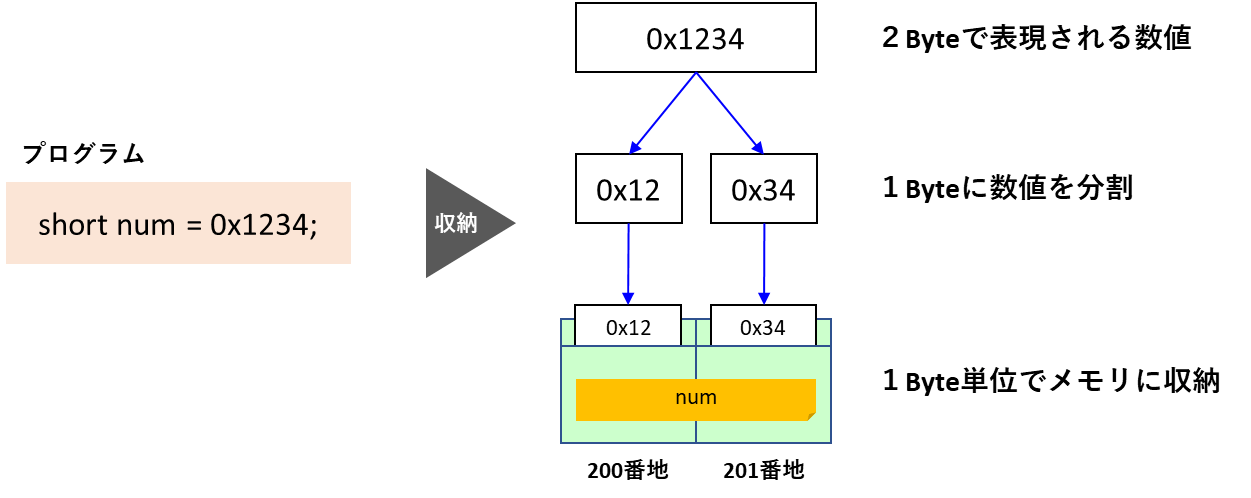
数値の上位となるバイト桁を、番地の小さい方から格納する方式となります。見た目の並びが「0x12」「0x34」なので、視認しやすい形ですね。
リトルエンディアン方式の特徴
続いてリトルエンディアンですが、なんとメモリの格納順番が逆転しています。
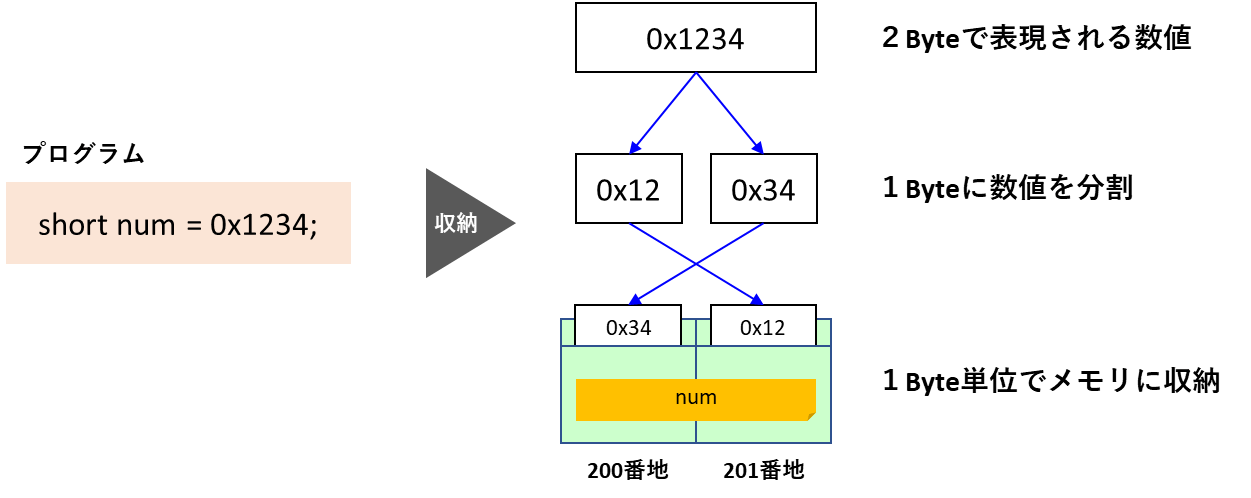
数値の下位バイトから順に格納するこの方式を「リトルエンディアン」と呼びます。
見た目の並びが「0x34」「0x12」なので、違和感を感じますがこのような方式もあるのです。
エンディアンの特徴まとめ
short型の2バイトだけでなく、long型の4バイトの数値も同様に格納順番が反転します。
long num = 0x12345678;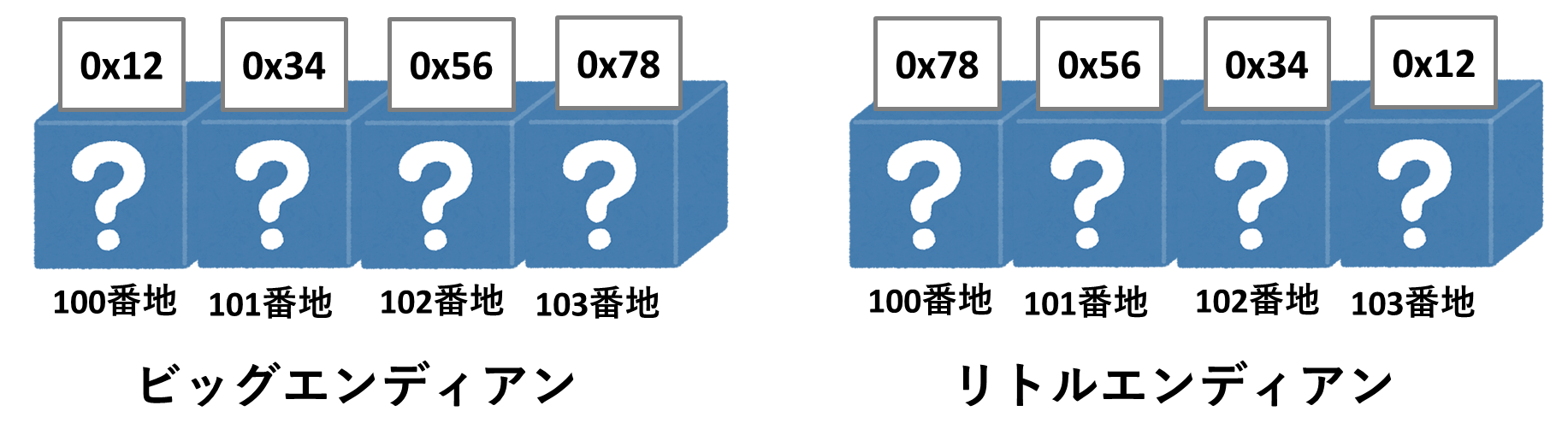
このようにshort型やlong型といった複数バイトで構成される数値を保存する場合、頭とお尻のどちらを先に格納するかという方式の違いを『エンディアン』と呼ぶのです。
エンディアンのことを『バイトオーダー』と呼んだりもします。
エンディアンを目で見て確認してみよう!
押忍!「リトルエンディアン」ってなんなんすかっ。あんな置き方おかしいっす!信じられないっす。自分をだまそうとしてるっすね。
確かにおかしく見えるけど、実際にそうなるんだよ。じゃあ、一緒に「リトルエンディアン」でメモリに格納される様子を見てみようね!
「ビッグエンディアン方式」と「リトルエンディアン方式」のどちらになるかはCPUに依存して決まります。
Windowsパソコンにおいてはintel社のCPUが搭載されているため、リトルエンディアン方式となります。
エンディアンの確認方法
実際にVisual Studioを使ってエンディアンの格納状況を確認してみましょう。
次のプログラムのreturn命令にブレークポイントを貼って、動かしてみてください。
#include <stdio.h>
int main(void)
{
short num = 0x1234;
return 0;
}確認手順
- [ウォッチ1]のウィンドウ画面に&numと入力する
- num変数の番地を確認する
- [メニュー]-[デバッグ]-[メモリ]-[メモリ1]を選択し、メモリウィンドウを表示する
- [メモリ1]ウィンドウにnumの番地を入力する
このようにすると、メモリウィンドウに指定番地のメモリデータを可視化できます。
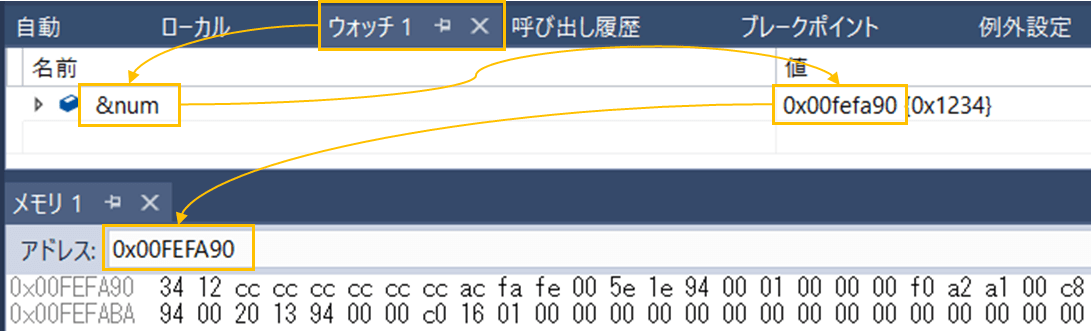
メモリの中身を見ると「34 12」と並んでいますね。これがリトルエンディアンです。
組み込み開発者は様々なCPUを扱うため、エンディアンを意識するシーンはWindows開発者よりも多いことになります。
エンディアンを意識する場面
押忍!「エンディアン」なんて今まで知らなかったっすけど、プログラムできてたっすよ。こんな知識って何かの役に立つっすか?
それはね、今まで役に立つシーンが出てこなかっただけで、必要なシーンがあるんだよ。必要な時に知らないと痛い目にあうから注意しようね。
皆さんはここまで「エンディアン」というものに関して、特に意識することなくプログラミングをしてきたことでしょう。
エンディアンなんて知識が必要なの?と感じているかもしれません。
それはエンディアンとは常に意識するものではなく、とある場面に遭遇した時に意識するものだからです。
エンディアンの知識が必要となるシーンとは
エンディアンの知識が必要となるシーンとは、「異なるエンディアン方式間で、情報をやり取りしなければならない時」です。
代表的なのが、コンピュータ間での通信や、ファイルやディスクといったメディア情報の読み取り時です。
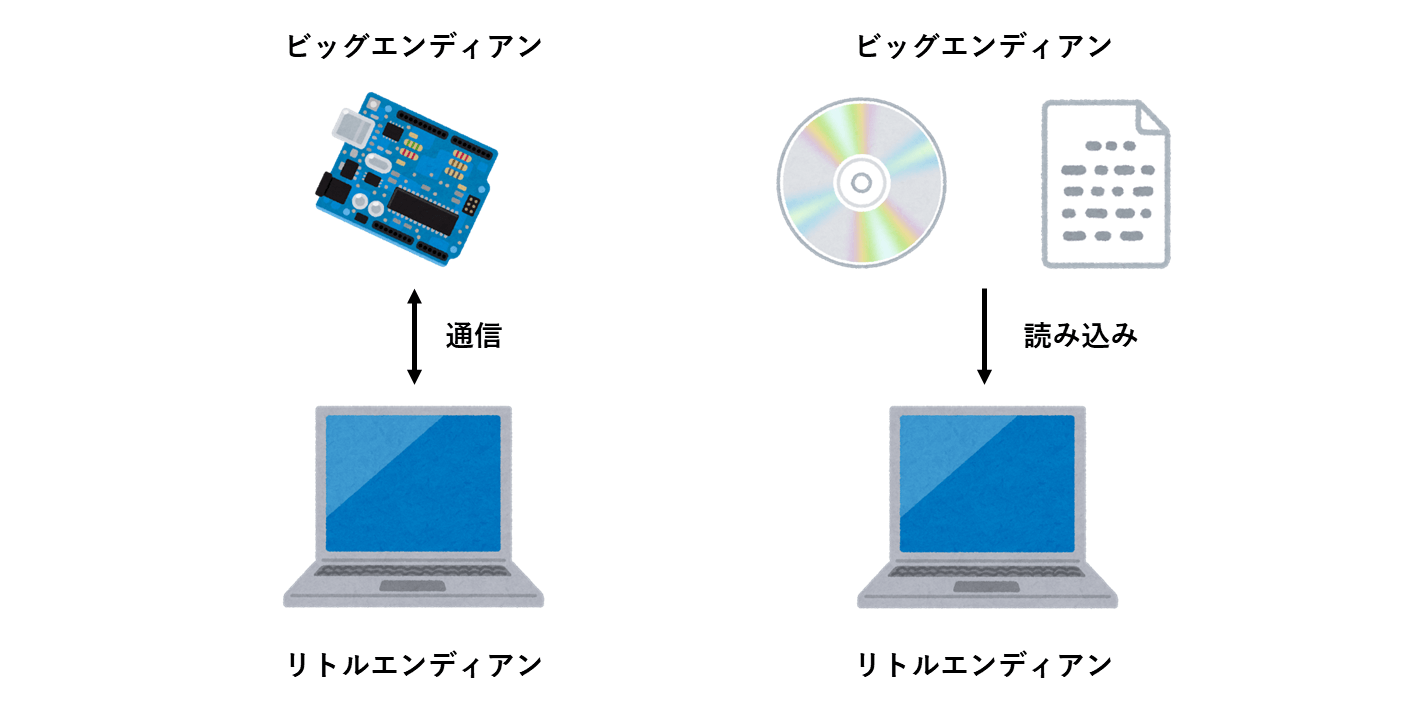
このように異なるエンディアン方式間でデータのやり取りを行うと、お互いのデータの並びが食い違うため、そのままでは正しくデータを扱えません。
どのように対応するかというと、データを読み書きする際に反転するプログラムを入れてエンディアン方式の違いを吸収します。
次のプログラムは疑似的にbig[4]としてビッグエンディアンで並んだデータを定義しています。num1には変換せず、num2にはエンディアン変換をして情報を取り込みます。
#include <stdio.h>
int main(void)
{
// 0x12345678をビッグエンディアン方式でメモリに配置したと仮定
unsigned char big[4] = { 0x12, 0x34, 0x56, 0x78 };
unsigned long num1 = 0; // 変換しない場合
unsigned long num2 = 0; // 変換した場合
// メモリ内容をそのまま
// long型で取り込む(変換なし)
memcpy(&num1, big, 4);
printf("num1:0x%x\n", num1);
// ビッグ --> リトル へ変換
// long型で取り込む(変換あり)
num2 = big[0] << 24 | big[1] << 16 | big[2] << 8 | big[3] << 0;
printf("num2:0x%x\n", num2);
return 0;
}エンディアン変換処理では、ビット演算子のシフト演算とOR演算を組み合わせてデータを構築しています。
動作結果は次のものになります。
num1:0x78563412
num2:0x12345678num2は変換処理を入れることで、リトルエンディアン環境でも「0x12345678」としてlong型変数に取り込むことができました。これがエンディアン変換処理です。
課題:エンディアンが学べたかを確認しよう
課題1
課題内容
次のようにビッグエンディアン形式で2Byteと4Byteのデータが順にメモリ上に定義されている。
// ビッグエンディアンで並んだ0x1234と0x89ABCDEFのデータ
const static unsigned char data[] = { 0x01, 0x23, 0x89, 0xAB, 0xCD, 0xEF };この2つのデータをunsigned short型とunsigned long型の変数num1とnum2へ取り込め。プログラムは次のものをベースに作成するものとする。変数や関数は自由に定義してもよいものとし、出力期待結果が表示されるようにせよ。
main.c
#include <stdio.h>
// ビッグエンディアンで並んだ0x1234と0x89ABCDEFのデータ
const static unsigned char data[] = { 0x01, 0x23, 0x89, 0xAB, 0xCD, 0xEF };
int main(void)
{
// 取り込み先の変数定義
// data[]から0x0123として取り込む
unsigned short num1 = 0;
// data[]から0x89ABCDEFとして取り込む
unsigned long num2 = 0;
// num1とnum2へエンディアン変換をして取り込む
// 取り込んだ情報を表示
printf("2Byte:0x%04X\n", num1);
printf("4Byte:0x%08X\n", num2);
return 0;
}出力期待結果
2Byte:0x0123
4Byte:0x89ABCDEFmain.c
#include <stdio.h>
// ビッグエンディアンで並んだ0x1234と0x89ABCDEFのデータ
const static unsigned char data[] = { 0x01, 0x23, 0x89, 0xAB, 0xCD, 0xEF };
// 2Byteと4Byteのビッグエンディアン ==> リトルエンディアン変換の関数マクロ
#define SWAP_ENDIAN_2BYTE(p) (p[0] << 8 | p[1])
#define SWAP_ENDIAN_4BYTE(p) (p[0] << 24 | p[1] << 16 | p[2] << 8 | p[3])
int main(void)
{
// 取り込み先の変数定義
// data[]から0x0123として取り込む
unsigned short num1 = 0;
// data[]から0x89ABCDEFとして取り込む
unsigned long num2 = 0;
const unsigned char * pData = data;
// num1とnum2へエンディアン変換をして取り込む
// 2Byte分をエンディアン変換して取得
num1 = SWAP_ENDIAN_2BYTE(pData);
// ポインタの照準を2Byteずらす
pData += sizeof(unsigned short);
// 4Byte分をエンディアン変換して取得
num2 = SWAP_ENDIAN_4BYTE(pData);
// 取り込んだ情報を表示
printf("2Byte:0x%04X\n", num1);
printf("4Byte:0x%08X\n", num2);
return 0;
}今回はエンディアン変換用の関数マクロを作成し取り込んでみました。取り込み方には他の方法もあるため、皆さんの結果も正しければOKでしょう。

