







こんにちは、ナナです。
文字列を加工するプログラムを作っている方は、英語の大文字と小文字を変換したいシーンに出くわすことがあるでしょう。
C言語には、標準ライブラリ関数に英語の大文字・小文字の変換関数が用意されています。
このような変換関数を使うこともできますし、大文字・小文字程度の変換であれば自作することも容易です。
本記事では次の疑問点を解消する内容となっています。
それでは、大文字・小文字の変換方法について学んでいきましょう。
大文字・小文字変換の標準ライブラリ関数
C言語には、英語の大文字・小文字を相互に変換するための標準ライブラリ関数が用意されています。
#include <ctype.h>
int toupper(int c);
int tolower(int c);「toupper」とは「to(~へ)」を「upper(大文字)」を省略した名前であり、「大文字へ変換する」という意味です。
「lower(小文字)」の場合は「小文字へ変換する」という意味になります。
関数名の頭には「is(~かどうか?)」とか「to(~へ)」といった、英語の文法を名称にしたものが結構あります。
このような名前の付け方は覚えておくと、自分の作った関数名にも応用できますよ!
toupper関数の仕様と使い方
引数で指定された英小文字を、英大文字へ変換するための関数です。
| includeファイル | ctype.h |
| 関数仕様 | int toupper(int c); |
| 第1引数 | 変換対象となる文字。 |
| 戻り値 | 大文字へ変換した文字。 |
| 特記事項 | 引数が英小文字以外の場合は、引数の文字がそのまま出力される。 |
使い方をプログラムで示しましょう。引数で入力した文字が、大文字に変換され戻り値として出力されます。
#include <stdio.h>
#include <ctype.h>
int main(void)
{
printf("a => %c\n", toupper('a'));
printf("f => %c\n", toupper('f'));
printf("A => %c\n", toupper('A'));
printf("$ => %c\n", toupper('$'));
return 0;
}a => A
f => F
A => A
$ => $英小文字以外の文字の場合は、何も変換されずに戻り値となることは知っておきましょう!
tolower関数の仕様と使い方
引数で指定された英大文字を、英小文字へ変換するための関数です。
| includeファイル | ctype.h |
| 関数仕様 | int tolower(int c); |
| 第1引数 | 変換対象となる文字。 |
| 戻り値 | 小文字へ変換した文字。 |
| 特記事項 | 引数が英大文字以外の場合は、引数の文字がそのまま出力される。 |
使い方をプログラムで示しましょう。引数で入力した文字が、小文字に変換され戻り値として出力されます。
#include <stdio.h>
#include <ctype.h>
int main(void)
{
printf("A => %c\n", tolower('A'));
printf("F => %c\n", tolower('F'));
printf("a => %c\n", tolower('a'));
printf("$ => %c\n", tolower('$'));
return 0;
}A => a
F => f
a => a
$ => $使い方は非常にシンプルですね。引数で渡した文字が、変換されて戻り値で出力される。典型的なサービスとしての関数形式です。
文字列を大文字・小文字へ一括変換するプログラム
実際の開発の中では、「文字」を変換するよりも、「文字列」を一括で変換したい場面の方が多いかもしれません。
このような場合は、皆さんが反復処理にて文字列内の文字を逐次変換する必要があります。
文字列を大文字へ変換するサンプルプログラム
それでは文字列「Hello World!」を、英大文字へと変換するサンプルプログラムを紹介しましょう。
#include <stdio.h>
#include <string.h>
#include <ctype.h>
int main(void)
{
size_t i;
char moji[] = "Hello World!";
for (i=0 ; i < strlen(moji) ; i++)
{
moji[i] = toupper(moji[i]);
}
printf("%s", moji);
return 0;
}HELLO WORLD!小文字へ変換したい場合は、「toupper関数」を「tolower関数」へ変更すればよいだけです。
このような文字列の場合は、C言語では1文字ずつを順に変換していくしかありません。
文字列を大文字へ変換する関数のサンプルプログラム
文字列を毎回反復処理で変換するのは面倒ですので、文字列を変換する関数を作ってしまえば便利ですね。
次のプログラムは、引数で指定された文字列を英大文字へと変換する「toupperString関数」の作成例です。
#include <stdio.h>
#include <string.h>
#include <ctype.h>
// 文字列を大文字へ変換する
int touppperString(char * str)
{
size_t i;
if (str == NULL)
{
return -1;
}
for (i = 0; i < strlen(str); i++)
{
str[i] = toupper(str[i]);
}
return 0;
}
int main(void)
{
char moji[] = "Hello World!";
touppperString(moji);
printf("%s", moji);
return 0;
}HELLO WORLD!サービスを受けたいmain関数側の処理は、かなり記述内容がすっきりしましたね。
プログラムというものはこのように便利な部品を少しずつ作っていき、開発を楽にしていくものなのです。
大文字・小文字へ変換する関数を自分で作ってみよう!
「toupper関数」や「tolower関数」は、処理内容としては大したことをしていません。
それでは自分で作成してみましょう!
このような標準ライブラリ関数の仕様を満たすように、自分で関数を作ってみると様々な関数の中身をイメージする力が付きます。
プログラミングを始めたばかりの人は、練習と思ってやってみるとよいですよ!
英大文字と英小文字の関係性とは?
文字というものはコンピュータの中では、ただの数値です。数値に対して特定の文字を紐づけているだけなのです。
英小文字や英大文字は「アスキーコード」と呼ばれる対応表にて一意に数値が決まっています。英小文字と英大文字の部分のみを下記に抜粋してみます。
| 16進数 | 英大文字 | 16進数 | 英小文字 |
|---|---|---|---|
| 0x41 | A | 0x61 | a |
| 0x42 | B | 0x62 | b |
| 0x43 | C | 0x63 | c |
| 0x44 | D | 0x64 | d |
| 0x45 | E | 0x65 | e |
| 0x46 | F | 0x66 | f |
| 0x47 | G | 0x67 | g |
| 0x48 | H | 0x68 | h |
| 0x49 | I | 0x69 | i |
| 0x4A | J | 0x6A | j |
| 0x4B | K | 0x6B | k |
| 0x4C | L | 0x6C | l |
| 0x4D | M | 0x6D | m |
| 0x4E | N | 0x6E | n |
| 0x4F | O | 0x6F | o |
| 0x50 | P | 0x70 | p |
| 0x51 | Q | 0x71 | q |
| 0x52 | R | 0x72 | r |
| 0x53 | S | 0x73 | s |
| 0x54 | T | 0x74 | t |
| 0x55 | U | 0x75 | u |
| 0x56 | V | 0x76 | v |
| 0x57 | W | 0x77 | w |
| 0x58 | X | 0x78 | x |
| 0x59 | Y | 0x79 | y |
| 0x5A | Z | 0x7A | z |
このように「文字」とは、何らかの数値と1対1で紐づいているのです。
皆さんこのアスキーコードをよく見てください。規則性があるのがわかりますか?
それでは答えです。「英大文字」と「小文字」の数値には、次の規則性があることがわかりますね。
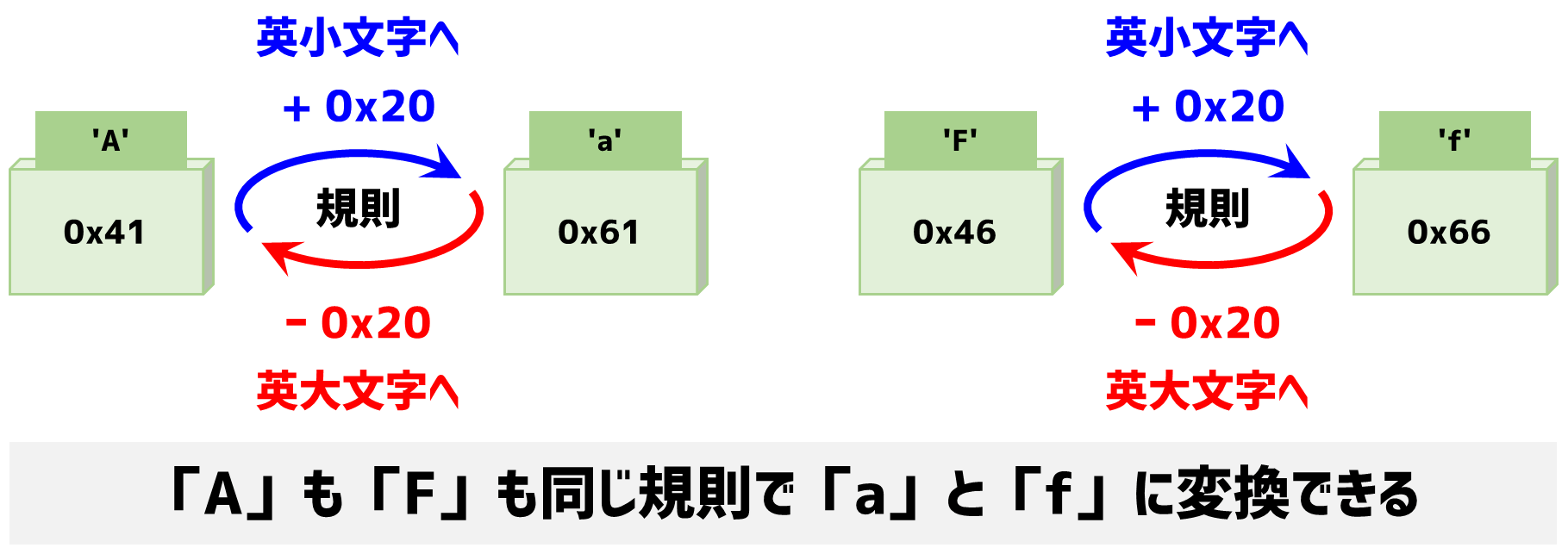
この規則性を利用して、英大文字・英小文字の変換プログラムを作っていきます。
「規則性を見つけ出す」という視点はプログラマーにとって非常に大事な力です。プログラムとは規則性を見つけ、コード化することだからです。
文字やアスキーコードについて詳しく知りたい方は『文字と文字列を図解【何が違うのこの2つ?解決します】』を読んでおくとよいでしょう!
大文字・小文字への自作変換関数のサンプルプログラム
それでは先ほどの規則性を利用して自作の大文字・小文字変換関数を作成してみましょう。
「toUpper関数」と「toLower関数」は次のように作ることができます。引数と戻り値の構成は同じものとしましょう。
#include <stdio.h>
int toUpper(int c)
{
// 英小文字の場合は英大文字へ変換
if ((c >= 'a') && (c <= 'z'))
{
return c - 0x20;
}
// 英小文字以外の場合
return c;
}
int toLower(int c)
{
// 英大文字の場合は英小文字へ変換
if ((c >= 'A') && (c <= 'Z'))
{
return c + 0x20;
}
// 英大文字以外の場合
return c;
}
int main(void)
{
printf("toUpper\n");
printf("a => %c\n", toUpper('a'));
printf("f => %c\n", toUpper('f'));
printf("z => %c\n", toUpper('z'));
printf("A => %c\n", toUpper('A'));
printf("$ => %c\n", toUpper('$'));
printf("toLower\n");
printf("A => %c\n", toLower('A'));
printf("F => %c\n", toLower('F'));
printf("Z => %c\n", toLower('Z'));
printf("a => %c\n", toLower('a'));
printf("$ => %c\n", toLower('$'));
return 0;
}toUpper
a => A
f => F
z => Z
A => A
$ => $
toLower
A => a
F => f
Z => z
a => a
$ => $それぞれ、入力文字の範囲をチェックし変換対象の文字かを確認します。変換対象であれば±0x20をすることで変換できます。
このように変換ルールをうまく使うことで、簡単にプログラミングすることができます。